Learning from Synthetic Data for Visual Grounding
Resumen de prensa
Investigadores de la Universidad Rice, la Universidad de Maryland y UC Irvine han desarrollado una canalización llamada SynGround que genera automáticamente grandes volúmenes de datos de entrenamiento sintéticos para ayudar a los sistemas de IA a conectar mejor las descripciones de texto con regiones específicas dentro de las imágenes — una tarea conocida como anclaje visual (visual grounding). El desafío que abordaron es que, si bien los pares imagen-texto pueden extraerse de la web a gran escala, las anotaciones a nivel de región necesarias para el anclaje (cuadros delimitadores que vinculan frases con áreas de la imagen) son costosas y lentas de producir a mano; el conjunto de datos Visual Genome, un benchmark estándar, requirió que 33,000 trabajadores tardaran seis meses en construirlo. SynGround evita este cuello de botella encadenando varios modelos preentrenados existentes: un gran modelo multimodal (LLaVA) genera descripciones detalladas de imágenes reales, esas descripciones se alimentan a un generador de texto a imagen (Stable Diffusion) para crear imágenes sintéticas, un LLM (Vicuna) extrae frases nominales cortas de las descripciones, y un detector de objetos de vocabulario abierto (GLIP) dibuja cuadros delimitadores alrededor de los objetos referenciados en las imágenes sintéticas. A través de experimentos sistemáticos, el equipo descubrió que las descripciones detalladas de imágenes producen imágenes sintéticas mucho mejores para esta tarea que la simple concatenación de texto o los resúmenes generados por LLM, y que las frases extraídas más cortas funcionan mejor que las más largas. Cuando se utilizaron para ajustar (fine-tune) dos modelos de visión y lenguaje listos para usar, ALBEF y BLIP, SynGround mejoró la precisión de localización en 4.81 y 17.11 puntos porcentuales respectivamente en los benchmarks RefCOCO+ y Flickr30k; combinar los datos sintéticos con datos reales anotados impulsó el rendimiento aún más, superando el estado del arte anterior. El trabajo también mostró que el enfoque puede funcionar con una dependencia mínima de imágenes reales y escala favorablemente con más datos, lo que sugiere que las canalizaciones sintéticas automatizadas podrían convertirse en un sustituto práctico de la costosa anotación humana en el entrenamiento de sistemas de anclaje.
resumen
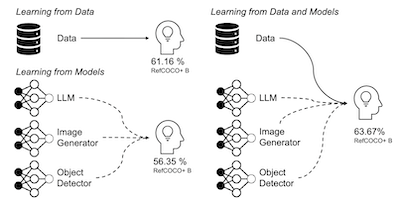
Este artículo investiga exhaustivamente la efectividad de los datos de entrenamiento sintéticos para mejorar las capacidades de los modelos de visión y lenguaje para anclar (grounding) descripciones textuales a regiones de imágenes. Exploramos diversas estrategias para generar de la mejor manera pares imagen-texto y tripletes imagen-texto-caja utilizando una serie de modelos preentrenados bajo diferentes configuraciones y grados variables de dependencia de datos reales. A través de análisis comparativos con datos sintéticos, reales y extraídos de la web, identificamos factores que contribuyen a las diferencias de rendimiento, y proponemos SynGround, una canalización (pipeline) eficaz para generar datos sintéticos útiles para el anclaje visual. Nuestros hallazgos muestran que SynGround puede mejorar las capacidades de localización de modelos de visión y lenguaje listos para usar y ofrece el potencial de generación de datos a una escala arbitrariamente grande. En particular, los datos generados con SynGround mejoran la precisión del juego de señalamiento (pointing game) de modelos preentrenados ALBEF y BLIP en 4.81% y 17.11% puntos porcentuales absolutos, respectivamente, en los benchmarks RefCOCO+ y Flickr30k.
detalles
cita
@inproceedings{he2025learning,
title = {Learning from Synthetic Data for Visual Grounding},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2025},
booktitle = {British Machine Vision Conference. BMVC 2025},
url = {https://arxiv.org/abs/2403.13804},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es SynGround y qué problema aborda? SynGround es una canalización de datos sintéticos para el anclaje visual que genera tripletes imagen-texto-caja para reducir la dependencia de costosas anotaciones de regiones realizadas por humanos.
- ¿Cómo genera SynGround datos de entrenamiento? Utiliza un modelo de descripción de imágenes para producir descripciones detalladas, un generador de texto a imagen para sintetizar imágenes, un LLM para extraer frases de anclaje cortas, y un detector de vocabulario abierto para producir cajas para esas frases.
- ¿Por qué son importantes las descripciones detalladas en la canalización? Los experimentos muestran que las descripciones detalladas Image2Text producen imágenes sintéticas más útiles para el anclaje que la simple concatenación de descripciones o los resúmenes Text2Text.
- ¿Cuánto mejora SynGround el anclaje visual? Los datos sintéticos de SynGround mejoran ALBEF en 4.81 puntos porcentuales y BLIP en 17.11 puntos porcentuales en promedio en las evaluaciones de juego de señalamiento (pointing-game) de RefCOCO+ y Flickr30k.
- ¿Puede SynGround reducir la dependencia de imágenes reales? Sí, el artículo reporta variantes con una dependencia mucho menor de imágenes reales y muestra que los datos sintéticos superan a datos comparables extraídos de la web para el anclaje visual.
Contribuciones principales
- El artículo proporciona un estudio sistemático de cómo sintetizar datos imagen-texto e imagen-texto-caja útiles para el anclaje visual, en lugar de solo demostrar una única receta de datos sintéticos.
- SynGround combina potentes modelos preentrenados para la generación de descripciones, generación de imágenes, extracción de frases y detección de vocabulario abierto en una canalización práctica para la supervisión escalable del anclaje.
- Los experimentos identifican decisiones de diseño concretas que importan, incluyendo descripciones detalladas de imágenes para la generación y frases extraídas más cortas para la supervisión del anclaje.
- El artículo muestra que los tripletes sintéticos pueden mejorar dos modelos de visión y lenguaje diferentes, ALBEF y BLIP, respaldando la generalidad del enfoque más allá de una sola arquitectura.
- La comparación con los datos de Conceptual Captions extraídos de la web muestra que los datos sintéticos dirigidos pueden ser más efectivos para el anclaje que simplemente escalar datos genéricos de imagen-texto.
Limitaciones y advertencias
- SynGround hereda algunas limitaciones de los generadores de descripciones, generadores de imágenes, LLM y detectores preentrenados que utiliza, pero eso también significa que la canalización puede mejorar naturalmente a medida que esos modelos componentes se vuelven más potentes.
- Las cajas y descripciones sintéticas no igualan completamente la precisión y diversidad de las anotaciones humanas de Visual Genome, sin embargo las ganancias de rendimiento muestran que ya son lo suficientemente útiles como para reducir sustancialmente la presión de anotación.
- Algunas personas o escenas generadas pueden contener artefactos visuales, lo cual es un problema conocido en la generación de imágenes sintéticas; las mejoras en el anclaje sugieren que la canalización sigue siendo eficaz a pesar de muestras imperfectas ocasionales.
- El estudio se centra principalmente en el anclaje visual de estilo juego de señalamiento (pointing-game) con ALBEF y BLIP, dejando los sistemas de predicción de frase-caja y las arquitecturas multimodales más nuevas como objetivos prometedores para el seguimiento.
- La canalización tiene múltiples etapas y decisiones de diseño, pero los estudios de ablación del artículo hacen que esas decisiones sean interpretables y proporcionan una sólida receta práctica para futuros conjuntos de datos sintéticos de anclaje.
Cómo interpretar este resultado
Este artículo se lee mejor como un sólido argumento empírico a favor de la supervisión sintética en el anclaje visual: SynGround muestra que los tripletes imagen-texto-caja cuidadosamente generados pueden mejorar significativamente la localización, aumentar los datos reales y ofrecer un camino escalable más allá de la costosa anotación de regiones realizada por humanos.