Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Resumen de prensa
Investigadores de la Universidad de Virginia y Salesforce Research han identificado un factor previamente pasado por alto que socava las técnicas comunes para eliminar el sesgo de género de los embeddings de palabras — la frecuencia estadística de las palabras en los datos de entrenamiento. Los embeddings de palabras, las representaciones numéricas del lenguaje utilizadas en innumerables aplicaciones de IA y procesamiento del lenguaje natural, son conocidos por codificar estereotipos de género de la sociedad, como asociar "programador" con los hombres y "ama de casa" con las mujeres. La solución dominante para este problema, un algoritmo llamado Hard Debias, funciona identificando y proyectando hacia fuera una "dirección de género" del espacio de embeddings, pero los investigadores descubrieron que la información de frecuencia de palabras incorporada en los embeddings distorsiona esa dirección de género antes de que pueda eliminarse limpiamente. Para abordar esto, construyeron un método de dos pasos llamado Double-Hard Debias, que primero elimina el componente relacionado con la frecuencia de los embeddings y luego aplica el procedimiento estándar Hard Debias. Al probarlo en embeddings GloVe y Word2Vec en tres benchmarks de sesgo estándar — incluyendo una tarea de resolución de correferencia, una prueba de asociación de palabras y una verificación de geometría basada en agrupamiento (clustering) — su enfoque redujo el sesgo de género medible de manera más sustancial que los métodos anteriores, con la brecha entre qué tan bien se desempeñaba un sistema de correferencia en oraciones estereotípicas de género frente a contraestereotípicas cayendo de 15.2 puntos porcentuales con GloVe sin modificar a solo 0.9 con su método, mientras que la calidad general del lenguaje en las tareas de analogía y categorización de palabras se mantuvo en gran medida intacta. El trabajo sugiere que limpiar los embeddings de palabras requiere prestar más atención a los artefactos estructurales que dejan las estadísticas del corpus.
resumen
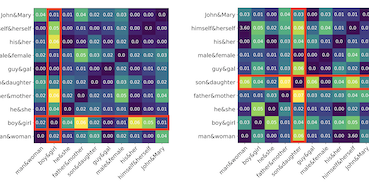
Los embeddings de palabras derivados de corpus generados por humanos heredan un fuerte sesgo de género que puede ser amplificado aún más por modelos posteriores. Algunos enfoques de mitigación de sesgo (debiasing) comúnmente adoptados, incluido el seminal algoritmo Hard Debias, aplican procedimientos de postprocesamiento que proyectan los embeddings de palabras preentrenados en un subespacio ortogonal a un subespacio de género inferido. Descubrimos que las regularidades del corpus agnósticas a la semántica, como la frecuencia de las palabras capturada por los embeddings, impactan negativamente el rendimiento de estos algoritmos. Proponemos una técnica simple pero efectiva, Double Hard Debias, que purifica los embeddings de palabras contra dichas regularidades del corpus antes de inferir y eliminar el subespacio de género. Los experimentos en tres benchmarks de mitigación de sesgo muestran que nuestro enfoque preserva la semántica distribucional de los embeddings de palabras preentrenados al tiempo que reduce el sesgo de género en un grado significativamente mayor que los enfoques anteriores.
detalles
cita
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}