FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
プレスリリース要約
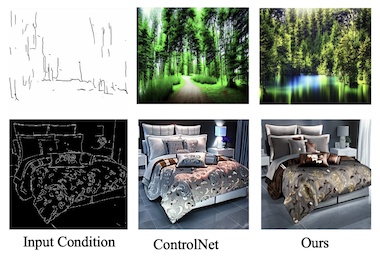
UC Santa Cruz、Amazon、UNC Chapel Hill、Rice大学、UCLAの研究者らは、複数のタイプの視覚的ガイダンスを同時に使用してAI画像生成器を制御する、より効率的な方法を開発しました。Stable Diffusionのような現在のテキストから画像への拡散モデルは、エッジマップ、深度マップ、セグメンテーションマップといった構造的入力によって操縦できますが、これらの制御可能なシステムの学習には通常、入力タイプが追加されるにつれて線形にスケールアップする相当な計算リソースが必要です。FlexEControlと呼ばれるチームの新しいシステムは、より広範な機械学習の文献からKronecker分解と呼ばれる数学的技術を借用し、それを使用して、入力ごとに別個のパラメータを学習するのではなく、異なる入力モダリティを扱うコンパクトな共有重みのセットを作成することで、これに取り組みます。その結果は、UniControlNetと呼ばれる主要な同等システムよりも学習可能なパラメータを41%、メモリを30%少なく使用しつつ、反復あたりの学習時間を約5.7秒から2.1秒に短縮するモデルです。生の効率性を超えて、FlexEControlはまた、複数の矛盾または冗長な入力(例えば、同じシーンの2つの異なるエッジマップ)を扱う場合にも優れた性能を発揮します。これは既存の手法が混乱したり一貫性のない画像を生成したりする傾向があるシナリオです。研究者らは、モデルに正しい空間領域に注意を払わせ、その出力を対応するテキストプロンプトと整合させる、2つの専門的な学習損失関数を追加することでこれを達成しました。人間による評価では、両方のシステムに同じタイプの複数の入力が与えられた場合、アノテーターはUniControlNetの出力よりもFlexEControlの出力を64%の確率で好みました。本研究が重要なのは、制御可能な画像生成をより安価にし、複雑で混合された入力をより扱えるようにすることが、限られた計算リソースで作業する開発者や研究者にとって、これらのツールへのアクセスを意味のある形で広げ得るためです。
要旨
制御可能なテキストから画像へ(T2I)の拡散モデルは、テキストプロンプトと、エッジマップのような他のモダリティの意味的入力の両方を条件として画像を生成します。しかしながら、現在の制御可能なT2I手法は、特に同一または多様なモダリティからの複数の入力を条件付けする場合に、効率性と忠実度に関連する課題に一般的に直面します。本論文では、制御可能なT2I生成のための、新しい柔軟かつ効率的な手法であるFlexEControlを提案します。FlexEControlの中核にあるのは独自の重み分解戦略であり、これによりさまざまな入力タイプの統合が合理化されます。このアプローチは、生成された画像の制御への忠実度を高めるだけでなく、マルチモーダルな条件付けに通常伴う計算オーバーヘッドを大幅に削減します。本アプローチは、Uni-ControlNetと比較して、学習可能なパラメータを41%、メモリ使用量を30%削減します。さらに、データ効率を2倍にし、さまざまなモダリティの複数の入力条件のガイダンスのもとで柔軟に画像を生成できます。
引用
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}