보도 자료 요약
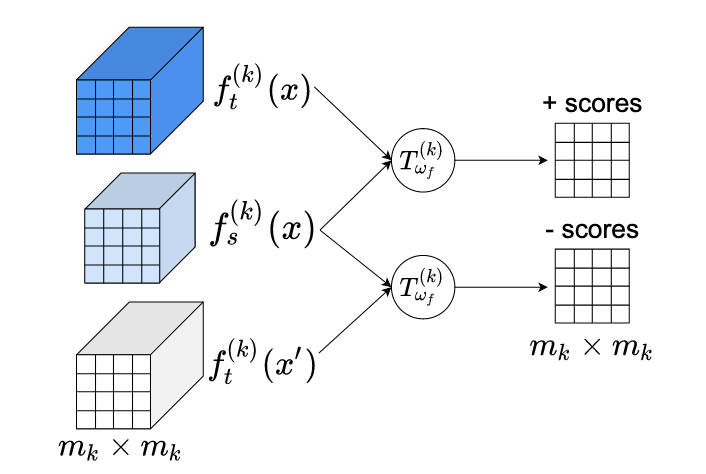
버지니아 대학교와 라이스 대학교의 연구진은 정확도를 너무 많이 희생하지 않으면서, 대규모 인공지능 모델을 휴대전화 및 기타 자원 제약 기기에서 실행할 수 있는 크기로 줄이는 새로운 기법을 개발했다. 지식 증류(knowledge distillation)로 알려진 이 분야의 핵심 과제는, 더 작은 "학생" 신경망이 더 크고 유능한 "교사" 신경망으로부터 유용한 정보를 흡수하도록 만드는 것이다. 기존 방법은 일반적으로 단순한 거리 척도를 사용하여 두 네트워크의 출력이나 중간 표현을 일치시킴으로써 이를 수행하는데, 교사와 학생의 내부 아키텍처가 매우 다를 때 어려움을 겪을 수 있다. MIMKD(Mutual Information Maximization Knowledge Distillation)라는 새로운 프레임워크는 정보 이론에 뿌리를 둔 대조 학습 목적함수, 구체적으로 Jensen-Shannon 발산 기반 추정기를 사용하여 두 네트워크 표현이 공유하는 상호 정보를 최종 전역 특징 수준과 더 세밀한 지역적·중간 특징 수준 모두에서 동시에 추정하고 최대화하는 다른 접근을 취한다. 실용적 이점은, Contrastive Representation Distillation과 같은 경쟁 방법과 달리 이 공식은 학습 중 수천 개가 아니라 단일 음성 표본(negative sample)만을 요구하여, 메모리 사용량이 훨씬 적고 중간 네트워크 계층에 더 적용 가능하다는 점이다. CIFAR-100 및 ImageNet 이미지 분류 벤치마크 테스트에서 MIMKD는 두 네트워크의 설계가 매우 다른 경우를 포함하여 광범위한 교사-학생 쌍 전반에 걸쳐 확립된 대안들을 일관되게 능가했으며, ResNet-50 교사를 사용하여 ShuffleNetV2의 정확도를 거의 5%포인트 끌어올리고 ImageNet의 ResNet-18을 기준선 대비 1.44%포인트 향상시켰다. 이는 이 접근법이 유능한 AI 모델을 엣지(edge)에서 배포하기에 더 실용적으로 만드는 데 기여할 수 있음을 시사하는 결과이다.
초록
본 연구에서 우리는 상호 정보 최대화 지식 증류(Mutual Information Maximization Knowledge Distillation, MIMKD)를 제안한다. 우리 방법은 대조적(contrastive) 목적함수를 사용하여 교사(teacher) 네트워크와 학생(student) 네트워크 간의 지역적 및 전역적 특징 표현의 상호 정보 하한을 동시에 추정하고 최대화한다. 우리는 광범위한 실험을 통해 이것이 더 성능이 뛰어나지만 계산 비용이 높은 모델로부터 지식을 전이하여 저용량 모델의 성능을 향상시키는 데 사용될 수 있음을 입증한다. 이는 계산 자원이 적은 기기에서 실행될 수 있는 더 나은 모델을 만드는 데 사용될 수 있다. 우리 방법은 유연하여, 임의의 네트워크 아키텍처를 가진 교사로부터 임의의 학생 네트워크로 지식을 증류할 수 있다. 우리의 실증 결과는 MIMKD가 서로 다른 용량, 서로 다른 아키텍처를 가진 광범위한 학생-교사 쌍 전반에 걸쳐, 그리고 학생 네트워크가 극도로 낮은 용량일 때 경쟁 접근법을 능가함을 보여준다. 우리는 ResNet-50으로부터 지식을 증류하여 ShufflenetV2로 CIFAR100에서 기준 정확도 69.8%에서 74.55%의 정확도를 얻을 수 있다. ImageNet에서는 ResNet-34 교사 네트워크를 사용하여 ResNet-18 네트워크를 68.88%에서 70.32% 정확도로(1.44%+) 향상시킨다.
인용
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}