보도 자료 요약
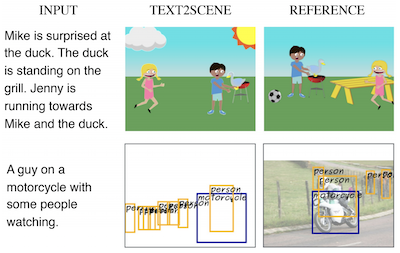
버지니아 대학교와 IBM의 Thomas J. Watson Research Center의 연구자들은 대부분의 경쟁 접근법이 의존하는 Generative Adversarial Networks(GAN)에 의존하지 않고 작성된 설명으로부터 시각적 장면을 자동으로 생성할 수 있는 Text2Scene이라는 시스템을 개발했다. 전체 이미지를 한 번에 합성하려 하는 대신, 이 시스템은 신중한 삽화가처럼 작동하여, 문장을 읽고 한 번에 하나씩 객체를 빈 캔버스에 배치하며, 각 단계마다 다음에 무엇을 추가할지, 어디에 둘지, 그리고 어떻게 보여야 할지를 결정한다. 이 모델은 장면을 구축하면서 입력 텍스트의 서로 다른 부분에 초점을 맞추기 위해 attention 메커니즘을 사용하므로, 설명이 "Jenny가 Mike를 향해 달려가고 있다"라고 말할 때, 시스템은 Jenny의 방향이 Mike가 이미 서 있는 곳에 달려 있음을 파악할 수 있다. 연구팀은 만화 클립아트 장면 생성, 사실적인 객체 레이아웃 맵 예측, 검색된 이미지 패치로부터 합성 사진 조립이라는 상당히 다른 세 가지 작업에 걸쳐 자신들의 접근법을 테스트했으며, 각 작업마다 사소한 수정만으로 동일한 기반 프레임워크를 사용했다. 정면 비교에서, Text2Scene은 대부분의 자동 품질 지표에서 GAN 기반 경쟁자들과 동등하거나 이를 능가했으며, 인간 평가자가 어느 이미지가 캡션과 더 잘 맞는지 판단했을 때 강력한 AttnGAN 모델을 포함한 모든 경쟁자를 능가했다. 이 연구는 악명 높게 까다로운 GAN 학습 과정을 회피한다는 점과, 모델이 왜 그런 선택을 했는지 이해하기 쉽게 만드는 해석 가능한 단계별 출력을 생성한다는 점 모두에서 주목할 만한데, 이는 순수하게 픽셀 기반인 생성 시스템이 일반적으로 결여한 특성이다.
초록
본 논문에서, 우리는 자연어 설명으로부터 다양한 형태의 구성적 장면 표현을 생성하는 모델인 Text2Scene을 제안한다. 최근의 연구들과 달리, 우리의 방법은 Generative Adversarial Networks(GAN)를 사용하지 않는다. 대신 Text2Scene은 입력 텍스트의 서로 다른 부분과 생성된 장면의 현재 상태에 주의를 기울임으로써, 매 시간 단계마다 객체와 그 속성(위치, 크기, 외형 등)을 순차적으로 생성하는 법을 학습한다. 우리는 사소한 수정만으로 제안된 프레임워크가 만화 같은 장면, 실제 이미지에 해당하는 객체 레이아웃, 그리고 합성 이미지를 포함한 다양한 형태의 장면 표현 생성을 처리할 수 있음을 보인다. 우리의 방법은 자동 지표를 사용했을 때 최첨단 GAN 기반 방법과 비교하여 경쟁력이 있을 뿐만 아니라 인간 판단을 기준으로 더 우수하며, 해석 가능한 결과를 생성하는 이점도 갖는다.
세부 정보
인용
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}