보도 자료 요약
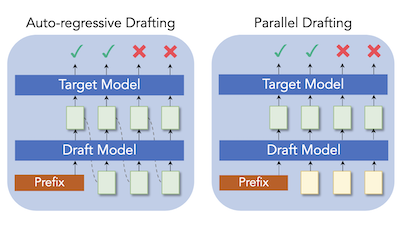
라이스 대학교와 Tencent AI Lab의 연구진은 대규모 언어 모델 추론을 더 빠르게 만드는 인기 있는 방법을 가속하는 ParallelSpec라는 새로운 기법을 개발했다. 근본적인 과제는, 작은 "초안" 모델을 사용하여 후보 텍스트를 빠르게 제안하면 더 큰 타깃 모델이 이를 병렬로 검증하는 이른바 추측적 디코딩 시스템이 여전히 그 작은 초안 생성기로 하여금 토큰을 한 번에 하나씩 생성하도록 강요하여, 초안 생성기가 예측하도록 요청받는 토큰이 많아질수록 더 길어지는 병목을 만든다는 점이다. 이를 해결하기 위해 연구팀은 특별히 학습된 자리표시자 "마스크" 토큰을 사용하여 모델이 순차적으로 실행하지 않고도 앞을 내다보도록 유도함으로써, 단일 순방향 패스에서 여러 미래 토큰을 동시에 예측하는 단일 경량 초안 모델을 구축했다. 또한 모델이 학습되는 방식과 추론 시점에 실제로 실행되는 방식 사이의 불일치를 방지하기 위해 그룹별 병렬 학습(group-wise parallel training)이라는 세심한 학습 절차를 설계했다. 이 접근법을 Medusa와 EAGLE라는 두 가지 확립된 추측적 디코딩 프레임워크에 적용했을 때, 번역, 요약, 수학적 추론, 질의응답을 포함한 다양한 텍스트 생성 작업에서 일관된 속도 향상을 제공했다. Llama-2-13B에서는 표준 자기회귀 생성 대비 2.84배의 속도에 도달했으며, Vicuna-7B에서 Medusa의 속도 향상을 약 63% 끌어올렸다. 이 연구는 단순히 얼마나 많은 토큰을 제안할지를 조정하는 것이 아니라 초안 작성 단계의 근본적인 비효율성을 다룬다는 점에서 의미가 있으며, 실시간 응용에서 무손실 LLM 가속을 더 실용적으로 만들 잠재력이 있다.
초록
추측적 디코딩(speculative decoding)은 대규모 언어 모델(LLM) 추론에 대한 효율적인 해결책으로 입증되었으며, 작은 초안 생성기(drafter)가 낮은 비용으로 미래 토큰을 예측하면 타깃 모델이 이를 병렬로 검증하는 방식으로 작동한다. 그러나 기존 연구의 대부분은 여전히 언어 모델링의 순차적 의존성을 유지하기 위해 토큰을 자기회귀적으로 초안 작성하며, 우리는 이것이 추측적 디코딩에서 막대한 계산 부담이라고 본다. 우리는 최신 추측적 디코딩 접근법의 자기회귀적 초안 작성 전략에 대한 대안인 ParallelSpec를 제시한다. 추측 단계에서의 자기회귀적 초안 작성과 달리, 우리는 효율적인 추측 모델 역할을 하도록 병렬 초안 생성기를 학습시킨다. ParallelSpec는 단일 모델을 사용하여 여러 미래 토큰을 효율적으로 병렬 예측하는 법을 학습하며, 최소한의 학습 비용으로 초안 생성기와 타깃 모델의 출력 분포를 정렬해야 하는 모든 추측적 디코딩 프레임워크에 통합될 수 있다. 실험 결과 ParallelSpec는 다양한 도메인의 텍스트 생성 벤치마크에서 기준 방법의 지연 시간을 최대 62%까지 가속하며, 제3자 평가 기준을 사용하여 Llama-2-13B 모델에서 전체적으로 2.84배의 속도 향상을 달성한다.
세부 정보
인용
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}