Improved Visual Grounding through Self-Consistent Explanations
Resumo do comunicado de imprensa
Pesquisadores da Rice University e da UC Irvine desenvolveram uma técnica para ajudar sistemas de IA a localizar com mais confiabilidade a posição de objetos em imagens quando recebem uma descrição textual — uma tarefa conhecida como ancoragem visual. O problema central que eles enfrentaram é que os modelos de visão e linguagem existentes, que aprendem a combinar imagens com texto, podem localizar corretamente um objeto como um "frisbee", mas falham quando o mesmo objeto é descrito usando uma palavra diferente, como "disco". Para resolver isso, a equipe criou uma abordagem de treinamento chamada SelfEQ (Self-consistency EQuivalence Tuning), que usa um modelo de linguagem de grande escala para gerar automaticamente paráfrases para legendas de imagens e então ajusta finamente o modelo visual de modo que tanto a frase original quanto sua paráfrase produzam a mesma região destacada na imagem. O método funciona sem exigir nenhuma anotação de caixa delimitadora, baseando-se, em vez disso, em mapas de explicação visual baseados em gradiente — especificamente o GradCAM — como uma forma de supervisão fraca. Testado em três benchmarks padrão, o SelfEQ melhorou a acurácia de localização em 4,69 pontos percentuais no Flickr30k, 7,68 pontos no ReferIt e uma média de 3,74 pontos no RefCOCO+, superando a maioria dos outros métodos que também dispensam a supervisão de caixas delimitadoras e até rivalizando com alguns que a utilizam. O resultado prático é um modelo que lida com um vocabulário mais amplo e localiza objetos de forma mais consistente — um progresso útil para aplicações como busca visual e interação humano-máquina que dependem de conectar a linguagem a partes específicas de uma imagem.
resumo
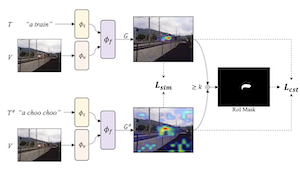
Modelos de visão e linguagem treinados para combinar imagens com texto podem ser combinados com métodos de explicação visual para apontar as localizações de objetos específicos em uma imagem. Nosso trabalho mostra que as capacidades de localização --"ancoragem"-- desses modelos podem ser ainda mais aprimoradas por meio do ajuste fino para explicações visuais autoconsistentes. Propomos uma estratégia para aumentar conjuntos de dados de texto-imagem existentes com paráfrases usando um modelo de linguagem de grande escala, e o SelfEQ, uma estratégia fracamente supervisionada sobre mapas de explicação visual para paráfrases que incentiva a autoconsistência. Especificamente, para uma frase textual de entrada, tentamos gerar uma paráfrase e ajustar finamente o modelo de modo que a frase e a paráfrase mapeiem para a mesma região na imagem. Postulamos que isso tanto expande o vocabulário que o modelo é capaz de lidar quanto melhora a qualidade das localizações de objetos destacadas por métodos de explicação visual baseados em gradiente (por exemplo, GradCAM). Demonstramos que o SelfEQ melhora o desempenho no Flickr30k, ReferIt e RefCOCO+ em relação a um forte método de referência e a vários trabalhos anteriores. Particularmente, em comparação com outros métodos que não usam nenhum tipo de anotação de caixa, obtemos 84,07% no Flickr30k (uma melhoria absoluta de 4,69%), 67,40% no ReferIt (uma melhoria absoluta de 7,68%) e 75,10%, 55,49% nos conjuntos de teste A e B do RefCOCO+ respectivamente (uma melhoria absoluta de 3,74% em média).
detalhes
citação
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- Que problema o SelfEQ aborda? O SelfEQ melhora a ancoragem visual fazendo com que um modelo de visão e linguagem localize frases equivalentes, como "frisbee" e "disco", na mesma região da imagem.
- Como o método funciona sem supervisão de caixa delimitadora? Ele usa mapas de explicação GradCAM de um modelo de visão e linguagem existente como supervisão fraca, e então treina o modelo para que uma frase original e sua paráfrase produzam mapas de localização consistentes.
- Por que paráfrases geradas por LLM são úteis aqui? As paráfrases expandem a redação que o modelo é capaz de lidar e criam pares de equivalência que ensinam o modelo a ancorar descrições semanticamente semelhantes de forma consistente.
- Qual o papel do objetivo do SelfEQ? O objetivo combina a similaridade de mapas de calor com um termo de consistência de região de interesse, de modo que os prompts parafraseados se alinhem espacialmente, evitando ao mesmo tempo mapas de explicação uniformes triviais.
- Quais benchmarks mostram o impacto do método? O artigo relata melhorias no Flickr30k, ReferIt e RefCOCO+, incluindo fortes resultados entre os métodos que não usam anotações de caixa.
Principais contribuições
- O artigo introduz o Self-consistency EQuivalence Tuning, um objetivo fracamente supervisionado para melhorar a ancoragem visual por meio de explicações consistentes entre textos parafraseados.
- Ele mostra que paráfrases geradas por LLM podem ser usadas como sinais de treinamento escaláveis para ancoragem visual, transformando a equivalência linguística em supervisão espacial útil.
- O método aprimora um pipeline de ancoragem baseado em ALBEF sem exigir caixas delimitadoras, máscaras de segmentação, detectores de objetos ou redes de proposta de caixas.
- O SelfEQ alcança ganhos substanciais sobre fortes bases fracamente supervisionadas, incluindo 84,07% no Flickr30k, 67,40% no ReferIt e melhor acurácia no pointing-game do RefCOCO+.
- As ablações esclarecem por que o ajuste de equivalência explícito importa: simplesmente adicionar paráfrases como pares imagem-texto extras é menos eficaz do que impor diretamente explicações visuais autoconsistentes.
Limitações e ressalvas
- O SelfEQ foi projetado para ancoragem fracamente supervisionada com mapas de explicação, de modo que complementa, em vez de substituir, sistemas de ancoragem totalmente supervisionados quando caixas de alta qualidade estão disponíveis.
- O método depende da qualidade das paráfrases geradas, mas o artigo utiliza uma estratégia clara de prompting e filtragem e mostra que os pares de equivalência resultantes proporcionam ganhos práticos.
- Por se basear em explicações no estilo GradCAM de um modelo de visão e linguagem de base, o desempenho pode refletir os pontos fortes do modelo subjacente; isso torna o SelfEQ especialmente valioso como uma estratégia de ajuste para aprimorar modelos existentes.
- A avaliação centra-se em benchmarks de ancoragem padrão e na acurácia do pointing-game, deixando cenários mais amplos do mundo real de busca visual, robótica e acessibilidade como aplicações futuras naturais.
- A abordagem concentra-se na ancoragem de frases e regiões, em vez do raciocínio visual de domínio aberto completo, o que mantém a contribuição bem direcionada e torna os ganhos relatados mais fáceis de interpretar.
Como interpretar este resultado
Este artigo é melhor compreendido como uma forte contribuição para a ancoragem visual fracamente supervisionada: o SelfEQ transforma a consistência de paráfrases em um sinal de treinamento prático, melhorando a acurácia de localização e a robustez de vocabulário sem precisar de caras anotações de localização de objetos.