Text2Scene: Generating Compositional Scenes from Textual Descriptions
Resumo do comunicado de imprensa
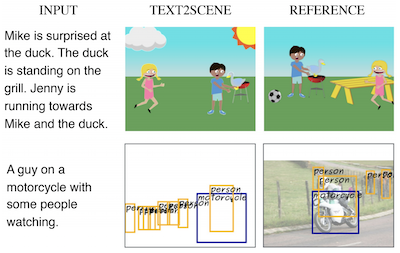
Pesquisadores da University of Virginia e do Thomas J. Watson Research Center da IBM desenvolveram um sistema chamado Text2Scene que pode gerar automaticamente cenas visuais a partir de descrições escritas — sem depender das Redes Generativas Adversariais, ou GANs, das quais a maioria das abordagens concorrentes depende. Em vez de tentar sintetizar uma imagem inteira de uma só vez, o sistema funciona mais como um ilustrador cuidadoso, lendo uma frase e depois posicionando objetos um de cada vez sobre uma tela em branco, decidindo a cada passo o que adicionar em seguida, onde colocá-lo e qual deve ser sua aparência. O modelo usa mecanismos de atenção para focar em diferentes partes do texto de entrada à medida que constrói a cena, de modo que, quando uma descrição diz "Jenny is running towards Mike", o sistema consegue deduzir que a orientação de Jenny depende de onde Mike já está posicionado. A equipe testou sua abordagem em três tarefas bastante diferentes — gerar cenas de clip-art em estilo de desenho animado, prever mapas realistas de layout de objetos e montar fotografias compostas a partir de fragmentos de imagens recuperados — usando o mesmo framework subjacente com apenas pequenas modificações para cada uma. Em comparações diretas, o Text2Scene igualou ou superou os rivais baseados em GANs na maioria das métricas automáticas de qualidade e superou todos eles, incluindo o forte modelo AttnGAN, quando avaliadores humanos julgaram quais imagens correspondiam melhor às suas legendas. O trabalho é notável tanto porque contorna o processo de treinamento de GANs, notoriamente delicado, quanto porque produz saídas interpretáveis, passo a passo, que tornam mais fácil entender por que o modelo fez as escolhas que fez — uma qualidade que os sistemas de geração puramente baseados em pixels geralmente não têm.
resumo
Neste artigo, propomos o Text2Scene, um modelo que gera várias formas de representações composicionais de cenas a partir de descrições em linguagem natural. Diferentemente de trabalhos recentes, nosso método NÃO usa Redes Generativas Adversariais (GANs). Em vez disso, o Text2Scene aprende a gerar sequencialmente objetos e seus atributos (localização, tamanho, aparência, etc.) a cada passo de tempo, atendendo a diferentes partes do texto de entrada e ao estado atual da cena gerada. Mostramos que, sob pequenas modificações, o framework proposto pode lidar com a geração de diferentes formas de representações de cenas, incluindo cenas no estilo de desenho animado, layouts de objetos correspondentes a imagens reais e imagens sintéticas. Nosso método não apenas é competitivo quando comparado a métodos de ponta baseados em GANs usando métricas automáticas e superior com base em julgamentos humanos, mas também tem a vantagem de produzir resultados interpretáveis.
detalhes
citação
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}