ParallelSpec: Parallel Drafter for Efficient Speculative Decoding
Resumo do comunicado de imprensa
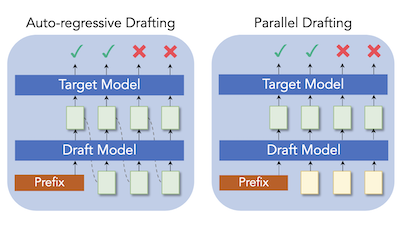
Pesquisadores da Rice University e do Tencent AI Lab desenvolveram uma nova técnica chamada ParallelSpec que acelera um método popular para tornar a inferência de modelos de linguagem de grande porte mais rápida. O desafio subjacente é que os chamados sistemas de decodificação especulativa — que usam um pequeno modelo de "rascunho" para propor rapidamente um texto candidato que um modelo-alvo maior então verifica em paralelo — ainda forçam esse pequeno rascunhador a gerar tokens um de cada vez, criando um gargalo que se torna mais longo quanto mais tokens o rascunhador é solicitado a prever. Para resolver isso, a equipe construiu um único modelo de rascunho leve que prevê múltiplos tokens futuros simultaneamente em uma única passagem para frente, usando tokens de "máscara" de marcação especialmente treinados para induzir o modelo a olhar adiante sem rodar sequencialmente. Eles também projetaram um procedimento de treinamento cuidadoso, chamado treinamento paralelo por grupos, para evitar incompatibilidades entre como o modelo é treinado e como ele realmente roda em tempo de inferência. Quando integrada a dois arcabouços de decodificação especulativa consolidados, Medusa e EAGLE, a abordagem proporcionou ganhos de velocidade consistentes em uma variedade de tarefas de geração de texto, incluindo tradução, sumarização, raciocínio matemático e resposta a perguntas; no Llama-2-13B, alcançou 2,84 vezes a velocidade da geração autorregressiva padrão e elevou o aumento de velocidade do Medusa no Vicuna-7B em cerca de 63 por cento. O trabalho é relevante porque aborda uma ineficiência fundamental no estágio de rascunho, em vez de simplesmente ajustar quantos tokens são propostos, potencialmente tornando a aceleração sem perdas de LLM mais prática para aplicações em tempo real.
resumo
A decodificação especulativa provou ser uma solução eficiente para a inferência de modelos de linguagem de grande porte (LLM), na qual o pequeno rascunhador prevê tokens futuros a baixo custo, e o modelo-alvo é aproveitado para verificá-los em paralelo. No entanto, a maioria dos trabalhos existentes ainda rascunha tokens de forma autorregressiva para manter a dependência sequencial na modelagem de linguagem, o que consideramos um enorme fardo computacional na decodificação especulativa. Apresentamos o ParallelSpec, uma alternativa às estratégias de rascunho autorregressivo nas abordagens de decodificação especulativa de ponta. Em contraste com o rascunho autorregressivo no estágio especulativo, treinamos um rascunhador paralelo para servir como um modelo especulativo eficiente. O ParallelSpec aprende a prever de forma eficiente múltiplos tokens futuros em paralelo usando um único modelo, e pode ser integrado a qualquer arcabouço de decodificação especulativa que exija alinhar as distribuições de saída do rascunhador e do modelo-alvo com custo mínimo de treinamento. Resultados experimentais mostram que o ParallelSpec acelera os métodos de linha de base em latência em até 62% em benchmarks de geração de texto de diferentes domínios, e alcança um aumento de velocidade geral de 2,84X no modelo Llama-2-13B usando critérios de avaliação de terceiros.
detalhes
citação
@article{xiao2024parallelspec,
title = {ParallelSpec: Parallel Drafter for Efficient Speculative Decoding},
author = {Xiao, Zilin and Zhang, Hongming and Ge, Tao and Ouyang, Siru and Ordonez, Vicente and Yu, Dong},
year = {2024},
journal = {arXiv preprint arXiv:2410.05589},
url = {https://arxiv.org/abs/2410.05589},
}