Chair Segments: A Compact Benchmark for the Study of Object Segmentation
News Release Summary
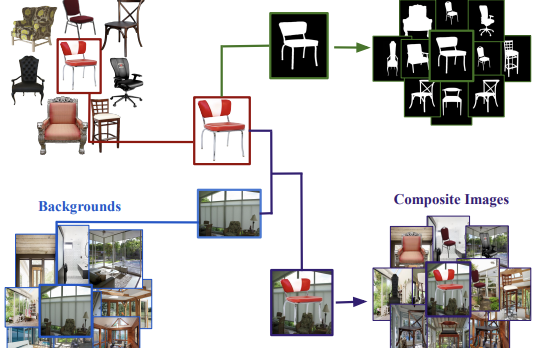
Researchers at the University of Virginia and collaborating institutions have released a new dataset called Chair Segments, designed to give computer vision scientists a faster, cheaper way to test image segmentation algorithms. The core problem they identified is that existing segmentation datasets — like COCO or PASCAL VOC — are large, expensive to annotate, and force models to simultaneously handle object recognition, localization, and pixel-level masking, making it hard to isolate and quickly iterate on segmentation-specific ideas. To get around this, the team built a semi-synthetic dataset of roughly 900 chair images with transparent backgrounds, composited onto 10,000 diverse indoor and outdoor scene images, producing 50,000 training composites with pixel-perfect ground truth masks that required no manual annotation. The researchers chose chairs deliberately: the category is notoriously difficult to segment due to thin, hollow, and self-occluding parts, and it ranks among the hardest in existing benchmarks. Their experiments showed that a U-Net model can be trained to full convergence on the dataset in about 30 minutes on a single GPU at 64×64 resolution — roughly the complexity level of CIFAR-10 for classification — while still meaningfully distinguishing between stronger and weaker architectures. Importantly, models pretrained on Chair Segments and then fine-tuned on the unrelated Object Discovery dataset (covering cars, horses, and airplanes) beat all previously published methods on that benchmark, suggesting the semi-synthetic data captures genuinely useful real-world features. The team also confirmed, for the first time in segmentation, a pattern previously observed in image classification: models fine-tuned from the same pretrained weights cluster together in the optimization landscape and transition smoothly between one another, while models trained from random initialization do not — a finding with practical implications for how segmentation models might be initialized and ensembled.
abstract
Over the years, datasets and benchmarks have had an outsized influence on the design of novel algorithms. In this paper, we introduce ChairSegments, a novel and compact semi-synthetic dataset for object segmentation. We also show empirical findings in transfer learning that mirror recent findings for image classification. We particularly show that models that are fine-tuned from a pretrained set of weights lie in the same basin of the optimization landscape. ChairSegments consists of a diverse set of prototypical images of chairs with transparent backgrounds composited into a diverse array of backgrounds. We aim for ChairSegments to be the equivalent of the CIFAR-10 dataset but for quickly designing and iterating over novel model architectures for segmentation. On Chair Segments, a U-Net model can be trained to full convergence in only thirty minutes using a single GPU. Finally, while this dataset is semi-synthetic, it can be a useful proxy for real data, leading to state-of-the-art accuracy on the Object Discovery dataset when used as a source of pretraining.
details
citation
@article{pintoalva2011chair,
title = {Chair Segments: A Compact Benchmark for the Study of Object Segmentation},
author = {Pinto-Alva, Leticia and Torres, Ian K. and Garcia, Rosangel and Yang, Ziyan and Ordonez, Vicente},
year = {2011},
journal = {arxiv:2011.14027 Nov 2020.},
url = {https://arxiv.org/abs/2012.01250},
}