FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Tóm tắt thông cáo báo chí
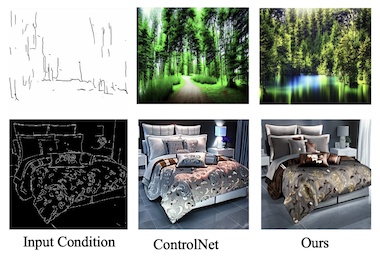
Các nhà nghiên cứu từ UC Santa Cruz, Amazon, UNC Chapel Hill, Rice University, và UCLA đã phát triển một cách hiệu quả hơn để điều khiển các bộ tạo ảnh AI bằng nhiều loại dẫn hướng thị giác đồng thời. Các mô hình khuếch tán text-to-image hiện tại như Stable Diffusion có thể được điều hướng bằng các đầu vào cấu trúc như bản đồ cạnh, bản đồ độ sâu, và bản đồ phân đoạn, nhưng việc huấn luyện các hệ thống có thể điều khiển này thường đòi hỏi tài nguyên tính toán đáng kể tăng tuyến tính khi thêm nhiều loại đầu vào hơn. Hệ thống mới của nhóm, có tên FlexEControl, giải quyết điều này bằng cách mượn một kỹ thuật toán học gọi là phân rã Kronecker từ tài liệu học máy rộng hơn, sử dụng nó để tạo ra một tập gọn nhẹ các trọng số được chia sẻ xử lý các phương thức đầu vào khác nhau thay vì học các tham số riêng cho từng phương thức. Kết quả là một mô hình sử dụng ít hơn 41% số tham số có thể huấn luyện và ít hơn 30% bộ nhớ so với một hệ thống tương đương hàng đầu có tên UniControlNet, đồng thời cắt giảm thời gian huấn luyện mỗi vòng lặp từ khoảng 5.7 giây xuống 2.1 giây. Ngoài hiệu suất thuần túy, FlexEControl còn hoạt động tốt hơn khi xử lý cùng lúc nhiều đầu vào mâu thuẫn hoặc dư thừa — chẳng hạn, hai bản đồ cạnh khác nhau của cùng một cảnh — một tình huống mà các phương pháp hiện có có xu hướng tạo ra các ảnh rối hoặc thiếu mạch lạc. Các nhà nghiên cứu đã đạt được điều này bằng cách thêm hai hàm mất mát huấn luyện chuyên biệt buộc mô hình chú ý đến đúng các vùng không gian và căn chỉnh các đầu ra của nó với các lời nhắc văn bản tương ứng. Trong các đánh giá của con người, người gán nhãn ưa chuộng các đầu ra của FlexEControl 64% thời gian so với của UniControlNet khi cả hai hệ thống được cung cấp nhiều đầu vào cùng loại. Công trình có ý nghĩa bởi việc làm cho việc tạo ảnh có thể điều khiển rẻ hơn và có khả năng xử lý các đầu vào phức tạp, hỗn hợp tốt hơn có thể mở rộng đáng kể khả năng tiếp cận các công cụ này cho các nhà phát triển và nghiên cứu làm việc với tài nguyên tính toán hạn chế.
tóm tắt
Các mô hình khuếch tán text-to-image (T2I) có thể điều khiển tạo ra các ảnh được điều kiện trên cả lời nhắc văn bản lẫn các đầu vào ngữ nghĩa của các phương thức khác như bản đồ cạnh. Tuy nhiên, các phương pháp T2I có thể điều khiển hiện tại thường đối mặt với các thách thức liên quan đến hiệu suất và độ trung thực, đặc biệt khi điều kiện trên nhiều đầu vào từ cùng một phương thức hoặc các phương thức đa dạng. Trong bài báo này, chúng tôi đề xuất một phương pháp Linh hoạt và Hiệu quả mới, FlexEControl, cho việc tạo T2I có thể điều khiển. Cốt lõi của FlexEControl là một chiến lược phân rã trọng số độc đáo, cho phép tích hợp tinh gọn nhiều loại đầu vào khác nhau. Cách tiếp cận này không chỉ nâng cao độ trung thực của ảnh được tạo ra so với điều khiển, mà còn giảm đáng kể chi phí tính toán thường gắn liền với việc điều kiện đa phương thức. Cách tiếp cận của chúng tôi đạt được mức giảm 41% số tham số có thể huấn luyện và 30% mức sử dụng bộ nhớ so với Uni-ControlNet. Hơn nữa, nó tăng gấp đôi hiệu quả dữ liệu và có thể tạo ra ảnh một cách linh hoạt dưới sự dẫn dắt của nhiều điều kiện đầu vào của các phương thức khác nhau.
trích dẫn
@article{he2025flexecontrol,
title = {FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation},
author = {He, Xuehai and Zheng, Jian and Fang, Jacob Zhiyuan and Piramuthu, Robinson and Bansal, Mohit and Ordonez, Vicente and Sigurdsson, Gunnar A and Peng, Nanyun and Wang, Xin Eric},
year = {2025},
journal = {Transactions of Machine Learning Research, TMLR 2025.},
url = {https://arxiv.org/abs/2405.04834},
}