Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation
Tóm tắt thông cáo báo chí
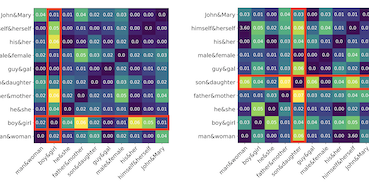
Các nhà nghiên cứu từ University of Virginia và Salesforce Research đã xác định một yếu tố trước đây bị bỏ qua làm suy yếu các kỹ thuật phổ biến để loại bỏ thiên kiến giới tính khỏi các word embedding — tần suất thống kê của các từ trong dữ liệu huấn luyện. Các word embedding, những biểu diễn số học của ngôn ngữ được dùng trong vô số ứng dụng AI và xử lý ngôn ngữ tự nhiên, được biết đến là mã hóa các khuôn mẫu giới tính xã hội, chẳng hạn như liên tưởng "programmer" với đàn ông và "homemaker" với phụ nữ. Cách khắc phục chủ đạo cho vấn đề này, một thuật toán gọi là Hard Debias, hoạt động bằng cách xác định và chiếu loại bỏ một "hướng giới tính" khỏi không gian embedding, nhưng các nhà nghiên cứu nhận thấy rằng thông tin tần suất từ được nướng sẵn vào các embedding làm bóp méo hướng giới tính đó trước khi nó có thể được loại bỏ một cách sạch sẽ. Để giải quyết điều này, họ đã xây dựng một phương pháp hai bước gọi là Double-Hard Debias, đầu tiên tước bỏ thành phần liên quan đến tần suất của các embedding và sau đó áp dụng quy trình Hard Debias tiêu chuẩn. Khi kiểm tra trên các embedding GloVe và Word2Vec qua ba benchmark thiên kiến tiêu chuẩn — bao gồm một nhiệm vụ phân giải đồng tham chiếu (coreference resolution), một bài kiểm tra liên tưởng từ, và một phép kiểm tra hình học dựa trên gom cụm — cách tiếp cận của họ đã giảm thiên kiến giới tính đo lường được một cách đáng kể hơn so với các phương pháp trước đó, với khoảng cách giữa mức độ một hệ thống đồng tham chiếu hoạt động tốt trên các câu rập khuôn giới tính so với phản rập khuôn giảm từ 15,2 điểm phần trăm với GloVe chưa được sửa đổi xuống chỉ còn 0,9 với phương pháp của họ, trong khi chất lượng ngôn ngữ chung trên các nhiệm vụ tương tự từ (word analogy) và phân loại vẫn được giữ nguyên phần lớn. Công trình cho thấy việc dọn dẹp các word embedding đòi hỏi phải chú ý kỹ hơn đến các hiện vật cấu trúc mà các thống kê kho ngữ liệu để lại.
tóm tắt
Các word embedding được dẫn xuất từ các kho ngữ liệu do con người tạo ra thừa hưởng thiên kiến giới tính mạnh mẽ, có thể bị khuếch đại thêm bởi các mô hình hạ nguồn. Một số cách tiếp cận khử thiên kiến thường được áp dụng, bao gồm thuật toán Hard Debias mang tính nền tảng, áp dụng các quy trình hậu xử lý chiếu các word embedding đã tiền huấn luyện vào một không gian con trực giao với một không gian con giới tính được suy ra. Chúng tôi phát hiện ra rằng các quy luật của kho ngữ liệu không phụ thuộc ngữ nghĩa, chẳng hạn như tần suất từ được nắm bắt bởi các word embedding, tác động tiêu cực đến hiệu năng của các thuật toán này. Chúng tôi đề xuất một kỹ thuật đơn giản nhưng hiệu quả, Double Hard Debias, làm thanh lọc các word embedding khỏi các quy luật kho ngữ liệu như vậy trước khi suy ra và loại bỏ không gian con giới tính. Các thí nghiệm trên ba benchmark giảm thiểu thiên kiến cho thấy cách tiếp cận của chúng tôi bảo toàn ngữ nghĩa phân phối của các word embedding đã tiền huấn luyện trong khi giảm thiên kiến giới tính ở mức độ lớn hơn đáng kể so với các cách tiếp cận trước đó.
chi tiết
trích dẫn
@inproceedings{wang2020double,
title = {Double-Hard Debias: Tailoring Word Embeddings for Gender Bias Mitigation},
author = {Wang, Tianlu and Lin, Xi Victoria and Rajani, Nazneen Fatema and McCann, Bryan and Ordonez, Vicente and Xiong, Caiming},
year = {2020},
booktitle = {Association for Computational Linguistics. ACL 2020},
url = {https://arxiv.org/abs/2005.00965},
}