Improved Visual Grounding through Self-Consistent Explanations
新闻稿摘要
莱斯大学和 UC Irvine 的研究人员开发了一种技术,帮助 AI 系统在给定文本描述时更可靠地定位图像中物体的位置——这一任务被称为视觉定位(visual grounding)。他们攻克的核心问题在于:现有的视觉-语言模型(学习将图像与文本相匹配)能够正确定位诸如“frisbee(飞盘)”这样的物体,但当同一物体用不同的词语描述时(比如“disc(圆盘)”)就会失败。为解决这一问题,研究团队创建了一种名为 SelfEQ(Self-consistency EQuivalence Tuning,自一致性等价微调)的训练方法,它利用大语言模型自动为图像描述生成释义,然后对视觉模型进行微调,使得原始短语及其释义在图像中产生相同的突出显示区域。该方法无需任何边界框标注,而是依靠基于梯度的视觉解释图——具体来说是 GradCAM——作为一种弱监督形式。在三个标准基准上的测试中,SelfEQ 将定位准确度在 Flickr30k 上提升了 4.69 个百分点,在 ReferIt 上提升了 7.68 个百分点,在 RefCOCO+ 上平均提升了 3.74 个百分点,超越了大多数同样不使用边界框监督的方法,甚至可与一些使用边界框监督的方法相媲美。其实际意义在于得到了一个能处理更广泛词汇并更一致地定位物体的模型——对于视觉搜索和人机交互等依赖将语言与图像特定部分相连接的应用而言,这是一项有益的进展。
摘要
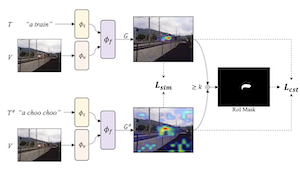
经过训练以将图像与文本相匹配的视觉-语言模型,可以与视觉解释方法相结合,从而指向图像中特定物体的位置。我们的工作表明,通过针对自一致的视觉解释进行微调,可以进一步提升这些模型的定位(“grounding”)能力。我们提出了一种策略,利用大语言模型为现有的文本-图像数据集增添释义(paraphrase),并提出 SelfEQ,一种针对释义视觉解释图的弱监督策略,以鼓励自一致性。具体而言,对于输入的文本短语,我们尝试生成一个释义,并对模型进行微调,使该短语及其释义映射到图像中的同一区域。我们认为,这既扩展了模型能够处理的词汇,又提升了基于梯度的视觉解释方法(如 GradCAM)所突出显示的物体位置的质量。我们证明,在 Flickr30k、ReferIt 和 RefCOCO+ 上,SelfEQ 相比一个强基线方法和若干先前工作均有所提升。特别地,与其他不使用任何边界框标注的方法相比,我们在 Flickr30k 上取得了 84.07%(绝对提升 4.69%),在 ReferIt 上取得了 67.40%(绝对提升 7.68%),在 RefCOCO+ 测试集 A 和 B 上分别取得了 75.10% 和 55.49%(平均绝对提升 3.74%)。
详情
引用
@inproceedings{he2024improved,
title = {Improved Visual Grounding through Self-Consistent Explanations},
author = {He, Ruozhen and Cascante-Bonilla, Paola and Yang, Ziyan and Berg, Alexander C. and Ordonez, Vicente},
year = {2024},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2024},
url = {https://arxiv.org/abs/2312.04554},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- SelfEQ 解决了什么问题?SelfEQ 通过让视觉-语言模型将等价短语(例如“frisbee”和“disc”)定位到同一图像区域,从而改进视觉定位。
- 该方法如何在没有边界框监督的情况下工作?它利用现有视觉-语言模型生成的 GradCAM 解释图作为弱监督,然后训练模型,使原始短语及其释义产生一致的定位图。
- 为什么 LLM 生成的释义在这里有用?这些释义扩展了模型能够处理的措辞,并创建了等价配对,从而教会模型一致地定位语义相似的描述。
- SelfEQ 目标函数的作用是什么?该目标函数将热图相似性与感兴趣区域一致性项相结合,使释义提示在空间上对齐,同时避免产生平凡的均匀解释图。
- 哪些基准展示了该方法的影响?论文报告了在 Flickr30k、ReferIt 和 RefCOCO+ 上的改进,包括在不使用边界框标注的方法中取得的强劲结果。
主要贡献
- 论文提出了 Self-consistency EQuivalence Tuning,一种弱监督目标函数,通过在释义文本之间保持一致的解释来改进视觉定位。
- 它表明 LLM 生成的释义可以用作视觉定位的可扩展训练信号,将语言上的等价性转化为有用的空间监督。
- 该方法改进了基于 ALBEF 的定位流程,而无需边界框、分割掩码、物体检测器或框提议网络。
- SelfEQ 相比强弱监督基线取得了显著提升,包括在 Flickr30k 上达到 84.07%、在 ReferIt 上达到 67.40%,并改进了 RefCOCO+ 的 pointing-game 准确度。
- 消融实验阐明了为什么显式的等价微调至关重要:仅仅将释义作为额外的图像-文本对加入,其效果不如直接强制实现自一致的视觉解释。
局限与注意事项
- SelfEQ 是为使用解释图的弱监督定位而设计的,因此当存在高质量边界框时,它是对完全监督定位系统的补充,而非替代。
- 该方法依赖于生成释义的质量,但论文采用了清晰的提示和过滤策略,并表明由此产生的等价配对带来了实际的提升。
- 由于它建立在基础视觉-语言模型的 GradCAM 式解释之上,其性能可能反映了底层模型的优势;这使得 SelfEQ 作为改进现有模型的微调策略尤为有价值。
- 评估集中在标准定位基准和 pointing-game 准确度上,将更广泛的现实世界视觉搜索、机器人和无障碍场景留作自然的后续应用方向。
- 该方法聚焦于短语和区域定位,而非完全开放式的视觉推理,这使其贡献定位明确,也使所报告的提升更易于解读。
如何理解这一结果
这篇论文最好被解读为对弱监督视觉定位的一项有力贡献:SelfEQ 将释义一致性转化为一种实用的训练信号,在无需昂贵的物体位置标注的情况下,提升了定位准确度和词汇鲁棒性。