新闻稿摘要
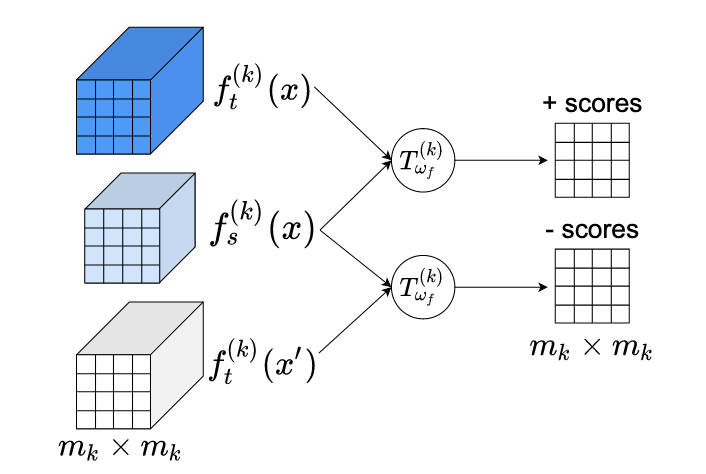
弗吉尼亚大学和莱斯大学的研究人员开发了一种新技术,能够将大型人工智能模型缩小到可在手机和其他资源受限设备上运行的规模,同时不会过多牺牲其准确性。该领域(称为知识蒸馏)的核心挑战在于,让一个较小的“学生”神经网络从一个更大、能力更强的“教师”网络中吸收有用信息。现有方法通常通过使用简单的距离度量来匹配两个网络的输出或中间表示来实现这一点,但当教师和学生具有非常不同的内部架构时,这种方法可能会遇到困难。这个名为 MIMKD(互信息最大化知识蒸馏)的新框架采用了一种不同的方法,使用一种植根于信息论的对比学习目标——具体来说是一种基于 Jensen-Shannon 散度的估计器——来同时估计并最大化两个网络表示之间共享的互信息,既包括最终全局特征层面,也包括更细粒度的局部和中间特征层面。一个实际优势是,与 Contrastive Representation Distillation 等竞争方法不同,这种表述在训练期间仅需要单个负样本,而非数千个,从而大大降低了内存占用,并更适用于中间网络层。在 CIFAR-100 和 ImageNet 图像分类基准上的测试中,MIMKD 在各种教师-学生配对中始终优于成熟的替代方法,包括两个网络设计差异很大的情况,它通过 ResNet-50 教师将 ShuffleNetV2 的准确率提升了近 5 个百分点,并将 ImageNet 上的 ResNet-18 相比其基线提升了 1.44 个百分点——这些结果表明,该方法有助于使强大的 AI 模型在边缘端的部署更加实用。
摘要
在这项工作中,我们提出了互信息最大化知识蒸馏(Mutual Information Maximization Knowledge Distillation, MIMKD)。我们的方法使用对比目标,同时估计并最大化教师网络与学生网络之间局部和全局特征表示互信息的下界。我们通过大量实验证明,这可用于通过从性能更强但计算成本更高的模型迁移知识,来提升低容量模型的性能。这可以用来产生更好的模型,使其能够在计算资源较低的设备上运行。我们的方法非常灵活,可以将知识从任意网络架构的教师蒸馏到任意学生网络。我们的实证结果表明,MIMKD 在各种容量不同、架构不同的学生-教师配对中,以及在学生网络容量极低的情况下,均优于竞争方法。我们能够通过从 ResNet-50 蒸馏知识,将 ShufflenetV2 在 CIFAR100 上的准确率从 69.8% 的基线提升到 74.55%。在 Imagenet 上,我们使用 ResNet-34 教师网络将 ResNet-18 网络的准确率从 68.88% 提升到 70.32%(提升 1.44%+)。
引用
@inproceedings{shrivastava2023estimating,
title = {Estimating and Maximizing Mutual Information for Knowledge Distillation},
author = {Shrivastava, Aman and Qi, Yanjun and Ordonez, Vicente},
year = {2023},
booktitle = {Workshop on Fair, Data Efficient and Trusted Computer Vision at CVPR 2023},
url = {https://arxiv.org/abs/2110.15946},
}