新闻稿摘要
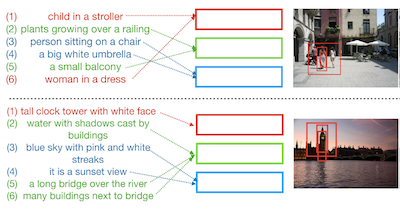
弗吉尼亚大学和 IBM Research 的研究人员开发了一个名为 Drill-down 的系统,让用户能够通过键入一系列自然语言描述来查找特定图像,每一条描述都进一步缩小搜索范围,而不是试图用单个查询捕捉所有内容。他们所攻克的问题是一个常见难题:当用户想要定位一张包含多个物体的复杂场景的非常特定的照片时,现有图像搜索工具会束手无策,因为将整个场景描述塞进一句话既困难又不精确。Drill-down 没有强制采用这种一次性方法,而是让用户从宽泛的描述开始——比如“一群人在公园里摆姿势”——然后在若干轮对话中逐步添加更具体的细节,例如“他们中间有一位新娘”,系统每次都会更新其结果。其关键技术贡献是一组紧凑的状态向量,用于存储和组织用户查询的历史,每个向量学习追踪场景的一个不同部分,而不是将所有内容压缩到单一表示中——这正是早期基于对话的检索系统的工作方式。至关重要的是,研究团队发现他们可以在不收集昂贵的人工标注搜索会话的情况下训练模型,而是使用来自 Visual Genome 数据集的现有图像区域描述作为真实用户查询的廉价替代。在模拟用户和真实人类用户上的测试均表明,Drill-down 在实际使用更少内存和更少参数的同时,优于竞争方法,并且超过 80% 的人类测试者在五轮之内成功定位了目标图像。这项工作表明,将图像搜索拆分为对话式的来回交互,是在大型多样化图像集合中检索高度特定图像的一条实用途径。
摘要
本文探索了使用自然语言查询进行交互式图像检索的任务,其中用户逐步提供输入查询以细化一组检索结果。此外,我们的工作在包含多个物体的复杂图像场景的背景下探索这一问题。我们提出了 Drill-down,一个有效的框架,它使用高效紧凑的状态表示来编码多个查询,显著扩展了当前用于单轮图像检索的方法。我们表明,使用多轮自然语言查询作为输入,在查找复杂场景中任意特定的图像方面出人意料地有效。此外,我们发现现有的带文本描述的图像数据集可以为这一任务提供一种出人意料地有效的弱监督形式。我们将我们的方法与现有的序列编码和嵌入网络进行了比较,在两个提出的基准上展示了优越的性能:使用区域描述作为查询的模拟场景下的自动图像检索,以及使用人类评估者真实查询的交互式图像检索。
详情
引用
@inproceedings{tan2019drill,
title = {Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries},
author = {Tan, Fuwen and Cascante-Bonilla, Paola and Guo, Xiaoxiao and Wu, Hui and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Conf. on Neural Information Processing Systems. NeurIPS 2019},
url = {https://arxiv.org/abs/1911.03826},
}