新闻稿摘要
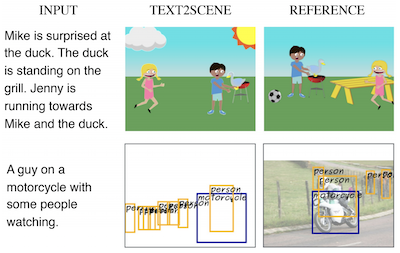
弗吉尼亚大学和 IBM Thomas J. Watson Research Center 的研究人员开发了一个名为 Text2Scene 的系统,它能够从书面描述自动生成视觉场景——无需依赖大多数竞争方法所依赖的生成对抗网络(GAN)。该系统并不试图一次性合成整张图像,而是更像一位细致的插画师,先读取一个句子,然后将对象一个接一个地放置到空白画布上,在每一步决定接下来添加什么、放在哪里以及它应该是什么样子。该模型使用注意力机制,在构建场景时聚焦于输入文本的不同部分,因此当描述说“Jenny 正朝 Mike 跑去”时,系统能够推断出 Jenny 的朝向取决于 Mike 已经站立的位置。团队在三个相当不同的任务上测试了他们的方法——生成卡通剪贴画场景、预测逼真的对象布局图,以及从检索到的图像块组装合成照片——使用同一个底层框架,每个任务仅作少量修改。在正面对比中,Text2Scene 在大多数自动质量指标上匹敌或击败了基于 GAN 的对手,并且当人类评估者判断哪些图像更符合其描述时,它优于所有对手,包括强大的 AttnGAN 模型。这项工作之所以引人注目,既因为它规避了 GAN 训练中出了名的难以驾驭的过程,也因为它产生了可解释的、逐步的输出,使人更容易理解模型为何做出这些选择——而纯基于像素的生成系统通常缺乏这种特质。
摘要
在本文中,我们提出 Text2Scene,一个能够从自然语言描述生成各种形式的组合式场景表示的模型。与近期的工作不同,我们的方法不使用生成对抗网络(GAN)。Text2Scene 转而学习在每个时间步顺序地生成对象及其属性(位置、大小、外观等),方法是关注输入文本的不同部分以及当前已生成场景的状态。我们表明,在稍作修改的情况下,所提出的框架可以处理不同形式的场景表示的生成,包括卡通式场景、对应真实图像的对象布局以及合成图像。我们的方法不仅在使用自动指标与最先进的基于 GAN 的方法比较时具有竞争力,而且在人类判断的基础上更胜一筹,同时还具有产生可解释结果的优势。
详情
引用
@inproceedings{tan2019text,
title = {Text2Scene: Generating Compositional Scenes from Textual Descriptions},
author = {Tan, Fuwen and Feng, Song and Ordonez, Vicente},
year = {2019},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2019},
url = {https://arxiv.org/abs/1809.01110},
}