Evolving Image Compositions for Feature Representation Learning
Zusammenfassung der Pressemitteilung
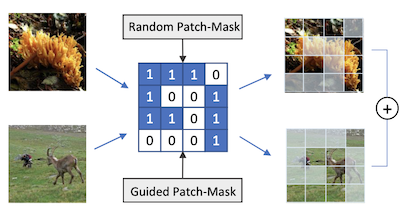
Forscher der University of Virginia und der Rice University haben eine Datenaugmentierungstechnik namens PatchMix entwickelt, die neuronalen Netzen zur Bilderkennung hilft, besser zu lernen, indem sie auf künstlich konstruierten Hybridbildern trainiert werden. Das Kernproblem besteht darin, dass Deep-Learning-Modelle für die visuelle Erkennung dazu neigen, ihre Trainingsdaten überzuanpassen, und obwohl bestehende Methoden wie Mixup und CutMix bereits Bildpaare miteinander verschmelzen, um dem entgegenzuwirken, sind sie in der Flexibilität, mit der sie diese Bilder kombinieren können, eingeschränkt. PatchMix begegnet dem, indem es zwei Bilder in ein Gitter aus gleich großen Patches zerlegt und Patches zwischen ihnen gemäß einer binären Maske austauscht und dem resultierenden zusammengesetzten Bild dann ein gemischtes Label zuweist, das proportional dazu ist, wie viele Patches aus jeder Quelle stammen. Das Team fügte außerdem eine sekundäre Verlustfunktion hinzu, die das Netz darauf trainiert, korrekt zu erkennen, zu welcher Klasse jeder einzelne Patch gehört, und nicht nur das Bild als Ganzes, was das Modell dazu zwingt, lokal bewusstere Repräsentationen aufzubauen. Darüber hinaus setzten die Forscher einen genetischen Suchalgorithmus ein, um automatisch zu entdecken, welche Paare von Bildkategorien am nützlichsten zusammen zu mischen sind und welche Gittermuster die anspruchsvollsten — und damit informativsten — Trainingsbeispiele erzeugen, und das alles, ohne das Modell für jede Kandidatenkonfiguration von Grund auf neu trainieren zu müssen. In Tests gegen Standard-Benchmarks übertraf ein mit PatchMix trainiertes ResNet-50-Modell die Basismodelle auf CIFAR-10, CIFAR-100, Tiny ImageNet und ImageNet und zeigte eine stärkere Transfer-Learning-Leistung über Aufgaben hinweg, darunter Objekterkennung, Szenenerkennung und Bildbeschreibung, was darauf hindeutet, dass die Methode universeller einsetzbare visuelle Merkmale erzeugt als konkurrierende Ansätze.
Zusammenfassung
Convolutional Neural Networks für die visuelle Erkennung benötigen große Mengen an Trainingsbeispielen und profitieren in der Regel von Datenaugmentierung. Diese Arbeit schlägt PatchMix vor, eine Methode zur Datenaugmentierung, die neue Beispiele erzeugt, indem sie Patches aus Bildpaaren in einem gitterartigen Muster zusammensetzt. Diesen neuen Beispielen werden Label-Werte zugewiesen, die proportional zur Anzahl der von jedem Bild übernommenen Patches sind. Anschließend fügen wir eine Reihe zusätzlicher Verlustfunktionen auf Patch-Ebene hinzu, um zu regularisieren und gute Repräsentationen sowohl auf Patch- als auch auf Bildebene zu fördern. Ein mit PatchMix auf ImageNet trainiertes ResNet-50-Modell zeigt überlegene Transfer-Learning-Fähigkeiten über eine breite Palette von Benchmarks hinweg. Obwohl PatchMix für das Mischen auf zufällige Paarungen und zufällige gitterartige Muster zurückgreifen kann, untersuchen wir die evolutionäre Suche als leitende Strategie, um gemeinsam optimale gitterartige Muster und Bildpaarungen zu entdecken. Zu diesem Zweck entwerfen wir eine Fitnessfunktion, die das erneute Trainieren eines Modells zur Bewertung jeder möglichen Wahl überflüssig macht. Auf diese Weise übertrifft PatchMix ein Basismodell auf CIFAR-10 (+1.91), CIFAR-100 (+5.31), Tiny Imagenet (+3.52) und ImageNet (+1.16).
Details
Zitation
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}