Evolving Image Compositions for Feature Representation Learning
新闻稿摘要
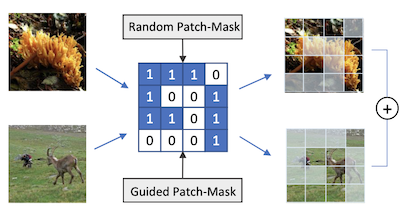
弗吉尼亚大学和莱斯大学的研究人员开发了一种名为 PatchMix 的数据增强技术,它通过在人工构造的混合图像上训练,帮助图像识别神经网络更好地学习。核心问题在于,用于视觉识别的深度学习模型往往会过拟合其训练数据,而尽管 Mixup 和 CutMix 等现有方法已经将成对图像融合在一起以对抗这一问题,它们在组合这些图像的灵活性上仍有局限。PatchMix 通过将两张图像切分为大小相等的图块网格,并根据一个二值掩码在它们之间交换图块来应对这一点,然后为所得的合成图像赋予一个与每个来源贡献图块数量成比例的混合标签。团队还添加了一个次级损失函数,训练网络正确识别每个单独图块所属的类别,而不仅仅是整张图像,这迫使模型构建更具局部感知的表示。更进一步,研究人员使用遗传搜索算法来自动发现哪些图像类别配对最有助于混合在一起,以及哪些网格模式能产生最具挑战性——因而也最具信息量——的训练样本,而所有这些都无需为每个候选配置从头重新训练模型。在标准基准上的测试中,使用 PatchMix 训练的 ResNet-50 模型在 CIFAR-10、CIFAR-100、Tiny ImageNet 和 ImageNet 上均超越了基线模型,并在物体检测、场景识别和图像字幕生成等任务上展现出更强的迁移学习性能,这表明该方法相比竞争方案能产生更具通用性的视觉特征。
摘要
用于视觉识别的卷积神经网络需要大量训练样本,并且通常能从数据增强中获益。本文提出 PatchMix,一种数据增强方法,它通过以网格状模式将成对图像的图块组合在一起来创建新样本。这些新样本被赋予与从每张图像借用图块数量成比例的标签分数。随后,我们在图块层级添加一组额外的损失,以进行正则化并鼓励在图块和图像两个层级都获得良好的表示。在 ImageNet 上使用 PatchMix 训练的 ResNet-50 模型在广泛的基准上展现出更优的迁移学习能力。尽管 PatchMix 可以依赖随机配对和随机网格状模式进行混合,我们仍探索了演化搜索作为一种引导策略,以联合发现最优的网格状模式和图像配对。为此,我们构思了一个适应度函数,绕过了为评估每个可能选择而重新训练模型的需要。通过这种方式,PatchMix 在 CIFAR-10(+1.91)、CIFAR-100(+5.31)、Tiny Imagenet(+3.52)和 ImageNet(+1.16)上均超越了基础模型。
详情
引用
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}