Evolving Image Compositions for Feature Representation Learning
Résumé du communiqué de presse
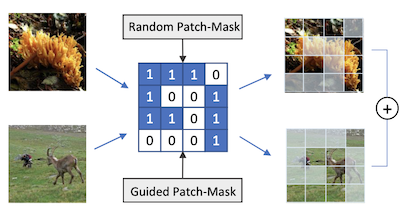
Des chercheurs de l'Université de Virginie et de l'Université Rice ont mis au point une technique d'augmentation de données appelée PatchMix qui aide les réseaux de neurones de reconnaissance d'images à mieux apprendre en s'entraînant sur des images hybrides construites artificiellement. Le problème central est que les modèles d'apprentissage profond pour la reconnaissance visuelle ont tendance à surapprendre leurs données d'entraînement, et bien que des méthodes existantes comme Mixup et CutMix mélangent déjà des paires d'images pour contrer cela, elles sont limitées dans la flexibilité avec laquelle elles peuvent combiner ces images. PatchMix résout ce problème en découpant deux images en une grille de patchs de taille égale et en échangeant des patchs entre elles selon un masque binaire, puis en attribuant à l'image composite résultante une étiquette mélangée proportionnelle au nombre de patchs provenant de chaque source. L'équipe a également ajouté une fonction de perte secondaire qui entraîne le réseau à identifier correctement la classe à laquelle appartient chaque patch individuel, et pas seulement l'image dans son ensemble, ce qui force le modèle à construire des représentations plus conscientes du contexte local. Allant plus loin, les chercheurs ont utilisé un algorithme de recherche génétique pour découvrir automatiquement quelles paires de catégories d'images sont les plus utiles à mélanger, et quels motifs de grille produisent les exemples d'entraînement les plus difficiles — et donc les plus informatifs — le tout sans avoir à réentraîner le modèle à partir de zéro pour chaque configuration candidate. Testé sur des benchmarks standard, un modèle ResNet-50 entraîné avec PatchMix a surpassé les modèles de référence sur CIFAR-10, CIFAR-100, Tiny ImageNet et ImageNet, et a affiché de meilleures performances d'apprentissage par transfert sur des tâches incluant la détection d'objets, la reconnaissance de scènes et la génération de légendes d'images, ce qui suggère que la méthode produit des caractéristiques visuelles plus polyvalentes que les approches concurrentes.
résumé
Les réseaux de neurones convolutifs pour la reconnaissance visuelle nécessitent de grandes quantités d'échantillons d'entraînement et bénéficient généralement de l'augmentation de données. Cet article propose PatchMix, une méthode d'augmentation de données qui crée de nouveaux échantillons en composant des patchs issus de paires d'images selon un motif en grille. Ces nouveaux échantillons se voient attribuer des scores d'étiquette proportionnels au nombre de patchs empruntés à chaque image. Nous ajoutons ensuite un ensemble de fonctions de perte supplémentaires au niveau des patchs pour régulariser et favoriser de bonnes représentations à la fois au niveau du patch et de l'image. Un modèle ResNet-50 entraîné sur ImageNet à l'aide de PatchMix présente des capacités d'apprentissage par transfert supérieures sur un large éventail de benchmarks. Bien que PatchMix puisse s'appuyer sur des appariements aléatoires et des motifs en grille aléatoires pour le mélange, nous explorons la recherche évolutionnaire comme stratégie directrice pour découvrir conjointement les motifs en grille et les appariements d'images optimaux. À cette fin, nous concevons une fonction de fitness qui élimine la nécessité de réentraîner un modèle pour évaluer chaque choix possible. De cette manière, PatchMix surpasse un modèle de base sur CIFAR-10 (+1,91), CIFAR-100 (+5,31), Tiny Imagenet (+3,52) et ImageNet (+1,16).
détails
citation
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}