Evolving Image Compositions for Feature Representation Learning
보도 자료 요약
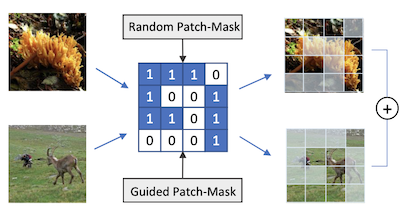
버지니아 대학교와 라이스 대학교의 연구진은 인공적으로 구성된 혼합 이미지로 학습함으로써 이미지 인식 신경망이 더 잘 학습하도록 돕는 PatchMix라는 데이터 증강 기법을 개발하였다. 핵심 문제는 시각 인식을 위한 딥러닝 모델이 학습 데이터에 과적합되는 경향이 있다는 것이며, Mixup이나 CutMix 같은 기존 방법이 이미 이미지 쌍을 함께 섞어 이에 맞서지만 이러한 이미지를 결합하는 유연성에 한계가 있다. PatchMix는 두 이미지를 동일한 크기의 패치 격자로 자르고 이진 마스크에 따라 그 사이에서 패치를 교환한 다음, 그 결과로 만들어진 합성 이미지에 각 출처에서 가져온 패치 수에 비례하는 혼합 레이블을 할당함으로써 이를 다룬다. 연구팀은 또한 각 개별 패치가 어떤 클래스에 속하는지를 이미지 전체뿐만 아니라 정확히 식별하도록 네트워크를 학습시키는 보조 손실 함수를 추가하였는데, 이는 모델이 더 지역적으로 인식하는 표현을 구축하도록 강제한다. 더 나아가, 연구진은 유전 탐색 알고리즘을 사용하여 어떤 이미지 범주 쌍을 함께 섞는 것이 가장 유용한지, 그리고 어떤 격자 패턴이 가장 까다로우면서 따라서 가장 유익한 학습 예시를 만드는지를, 후보 구성마다 모델을 처음부터 재학습할 필요 없이 자동으로 발견하였다. 표준 벤치마크에 대해 테스트한 결과, PatchMix로 학습된 ResNet-50 모델은 CIFAR-10, CIFAR-100, Tiny ImageNet, ImageNet에서 베이스라인 모델을 능가하였으며, 객체 탐지, 장면 인식, 이미지 캡셔닝을 포함한 과제 전반에 걸쳐 더 강한 전이 학습 성능을 보여, 이 방법이 경쟁 접근법보다 더 범용적인 시각 특징을 생성함을 시사한다.
초록
시각 인식을 위한 합성곱 신경망은 많은 양의 학습 샘플을 필요로 하며 일반적으로 데이터 증강으로부터 이점을 얻는다. 본 논문은 이미지 쌍으로부터 패치를 격자 형태의 패턴으로 구성하여 새로운 샘플을 만드는 데이터 증강 방법인 PatchMix를 제안한다. 이 새로운 샘플들에는 각 이미지에서 가져온 패치의 수에 비례하는 레이블 점수가 할당된다. 그런 다음 우리는 패치 수준에서 추가적인 손실 집합을 더하여 정규화하고 패치 및 이미지 수준 모두에서 좋은 표현을 장려한다. PatchMix를 사용하여 ImageNet에서 학습된 ResNet-50 모델은 다양한 벤치마크 전반에 걸쳐 우수한 전이 학습 능력을 보인다. PatchMix는 혼합을 위해 랜덤 짝짓기와 랜덤 격자 형태 패턴에 의존할 수 있지만, 우리는 최적의 격자 형태 패턴과 이미지 짝짓기를 함께 발견하기 위한 안내 전략으로 진화적 탐색을 탐구한다. 이를 위해, 우리는 가능한 각 선택을 평가하기 위해 모델을 재학습할 필요를 우회하는 적합도 함수를 고안한다. 이러한 방식으로 PatchMix는 CIFAR-10(+1.91), CIFAR-100(+5.31), Tiny Imagenet(+3.52), ImageNet(+1.16)에서 기본 모델을 능가한다.
세부 정보
인용
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}