Evolving Image Compositions for Feature Representation Learning
Sintesi del comunicato stampa
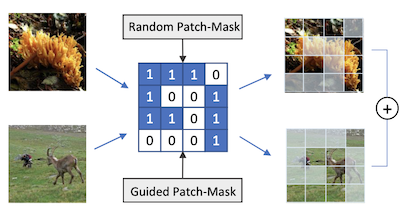
Ricercatori di University of Virginia e Rice University hanno sviluppato una tecnica di data augmentation chiamata PatchMix che aiuta le reti neurali per il riconoscimento di immagini ad apprendere meglio addestrandosi su immagini ibride costruite artificialmente. Il problema centrale è che i modelli di deep learning per il riconoscimento visivo tendono a sovradattarsi ai dati di addestramento e, sebbene metodi esistenti come Mixup e CutMix combinino già coppie di immagini per contrastare questo fenomeno, essi sono limitati nella flessibilità con cui possono combinare tali immagini. PatchMix affronta il problema suddividendo due immagini in una griglia di patch di uguale dimensione e scambiando le patch tra esse secondo una maschera binaria, assegnando poi all'immagine composita risultante un'etichetta mista proporzionale a quante patch provengono da ciascuna fonte. Il team ha inoltre aggiunto una seconda funzione di loss che addestra la rete a identificare correttamente a quale classe appartiene ciascuna singola patch, non solo l'immagine nel suo complesso, costringendo il modello a costruire rappresentazioni più consapevoli a livello locale. Spingendosi oltre, i ricercatori hanno usato un algoritmo di ricerca genetica per scoprire automaticamente quali coppie di categorie di immagini siano più utili da combinare e quali schemi a griglia producano gli esempi di addestramento più impegnativi — e quindi più informativi — il tutto senza dover ri-addestrare il modello da zero per ogni configurazione candidata. Testato sui benchmark standard, un modello ResNet-50 addestrato con PatchMix ha superato i modelli di base su CIFAR-10, CIFAR-100, Tiny ImageNet e ImageNet, e ha mostrato prestazioni di transfer learning più solide in compiti come il rilevamento di oggetti, il riconoscimento di scene e la generazione di didascalie per immagini, suggerendo che il metodo produce caratteristiche visive più generaliste rispetto agli approcci concorrenti.
abstract
Le reti neurali convoluzionali per il riconoscimento visivo richiedono grandi quantità di campioni di addestramento e di solito traggono beneficio dalla data augmentation. Questo articolo propone PatchMix, un metodo di data augmentation che crea nuovi campioni componendo patch provenienti da coppie di immagini secondo uno schema a griglia. A questi nuovi campioni vengono assegnati punteggi di etichetta proporzionali al numero di patch prese in prestito da ciascuna immagine. Aggiungiamo poi un insieme di loss aggiuntive a livello di patch per regolarizzare e per favorire buone rappresentazioni sia a livello di patch sia a livello di immagine. Un modello ResNet-50 addestrato su ImageNet utilizzando PatchMix mostra capacità di transfer learning superiori su un'ampia gamma di benchmark. Sebbene PatchMix possa basarsi su abbinamenti casuali e schemi a griglia casuali per il mixing, esploriamo la ricerca evolutiva come strategia guida per scoprire congiuntamente gli schemi a griglia e gli abbinamenti di immagini ottimali. A questo scopo, concepiamo una funzione di fitness che evita la necessità di ri-addestrare un modello per valutare ogni possibile scelta. In questo modo, PatchMix supera un modello di base su CIFAR-10 (+1,91), CIFAR-100 (+5,31), Tiny Imagenet (+3,52) e ImageNet (+1,16).
dettagli
citazione
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}