Taming Data and Transformers for Audio Generation
Zusammenfassung der Pressemitteilung
Forschende der Rice University und von Snap Inc. haben einen hartnäckigen Engpass bei KI-generierten Umgebungsgeräuschen angegangen — den Mangel an großen, gut beschrifteten Trainingsdaten und Modellen, die sich nicht verbessern, wenn sie größer werden. Um das Datenproblem zu lösen, entwickelte das Team eine automatisierte Pipeline, die Umgebungsaudio-Clips aus bestehenden YouTube-basierten Videodatensätzen gewinnt, indem sie Segmente identifiziert, in denen keine Sprach- oder Musiktranskription vorhanden ist, und so die Notwendigkeit umgeht, teure Klassifikatoren herunterzuladen und auf rohem Videomaterial auszuführen. Das Ergebnis ist AutoReCap-XL, ein Datensatz mit 47 Millionen Umgebungsaudio-Clips mit Textbeschreibungen, etwa 75-mal größer als das, was zuvor verfügbar war. Um diese Beschreibungen zu erzeugen, entwickelten sie AutoCap, ein Audio-Beschriftungsmodell, das ein Q-Former-Modul zusammen mit visuellen Metadaten wie Videotiteln und Bildunterschriften auf Frame-Ebene einbezieht und einen CIDEr-Wert von 83,2 auf dem standardmäßigen AudioCaps-Benchmark erreicht — eine Verbesserung von 3,2 % gegenüber früheren Methoden. Auf der Generierungsseite führten sie GenAu ein, ein Transformer-basiertes Diffusionsmodell, das auf 1,25 Milliarden Parameter hochskaliert wurde und eine ursprünglich für Video konzipierte "FIT"-Architektur übernimmt, wobei lokale und globale Attention-Schichten verwendet werden, um die Rechenleistung auf informative Audiosegmente zu konzentrieren, anstatt sie gleichmäßig über stille oder redundante Teile zu verteilen. Im Vergleich zu vergleichbaren Baselines verbesserte GenAu den Inception Score um 11,1 %, die Fréchet Audio Distance um 4,7 % und den CLAP-Text-Ausrichtungswert um 13,5 % und verbesserte sich — anders als frühere große Audiomodelle — kontinuierlich, sowohl mit zunehmender Modellgröße als auch mit zunehmender Datensatzgröße, was darauf hindeutet, dass das Feld endlich ein Rezept dafür haben könnte, die Generierung von Umgebungsgeräuschen so zu skalieren, wie es bei der Bild- und Videogenerierung bereits geschehen ist.
Zusammenfassung
Die Skalierbarkeit von Generatoren für Umgebungsgeräusche wird durch Datenknappheit, unzureichende Qualität der Bildunterschriften und begrenzte Skalierbarkeit der Modellarchitektur beeinträchtigt. Diese Arbeit begegnet diesen Herausforderungen, indem sie sowohl die Daten- als auch die Modellskalierung vorantreibt. Zunächst schlagen wir eine effiziente und skalierbare Pipeline zur Datensammlung vor, die auf die Generierung von Umgebungsaudio zugeschnitten ist und in AutoReCap-XL resultiert, dem größten Audio-Text-Datensatz für Umgebungsgeräusche mit über 47 Millionen Clips. Um hochwertige textuelle Annotationen bereitzustellen, schlagen wir AutoCap vor, ein hochwertiges Modell zur automatischen Audio-Beschriftung. Durch die Verwendung eines Q-Former-Moduls und die Nutzung von Audio-Metadaten verbessert AutoCap die Qualität der Bildunterschriften erheblich und erreicht einen CIDEr-Wert von $83.2$, eine Verbesserung von $3.2\%$ gegenüber früheren Beschriftungsmodellen. Schließlich schlagen wir GenAu vor, eine skalierbare, Transformer-basierte Audio-Generierungsarchitektur, die wir auf 1,25 Mrd. Parameter hochskalieren. Wir demonstrieren ihre Vorteile sowohl bei der Datenskalierung mit synthetischen Bildunterschriften als auch bei der Skalierung der Modellgröße. Im Vergleich zu Basis-Audiogeneratoren, die in ähnlicher Größe und mit ähnlichem Datenumfang trainiert wurden, erzielt GenAu deutliche Verbesserungen von $4.7\%$ beim FAD-Wert, $11.1\%$ beim IS und $13.5\%$ beim CLAP-Wert. Unser Code, unsere Modell-Checkpoints und unser Datensatz sind öffentlich verfügbar.
Details
Zitation
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Welches Problem löst diese Arbeit? Sie adressiert die wesentlichen Hindernisse für die skalierbare Generierung von Umgebungsgeräuschen: knappe Audio-Text-Daten, schwache Qualität der Bildunterschriften und Generator-Architekturen, die nicht zuverlässig von der Skalierung profitiert haben.
- Was ist AutoReCap-XL? AutoReCap-XL ist ein sehr großer Audio-Text-Datensatz für Umgebungsgeräusche mit über 47 Millionen Clips, die durch das Filtern von Online-Videosegmenten nach Audio ohne Sprache und ohne Musik gesammelt und automatisch neu beschriftet wurden.
- Was ist AutoCap? AutoCap ist ein Modell zur automatischen Audio-Beschriftung, das Audiomerkmale, einen Q-Former, BART-Decodierung und Metadaten wie Videotitel und visuelle Bildunterschriften kombiniert, um hochwertigere Audiobeschreibungen zu erzeugen.
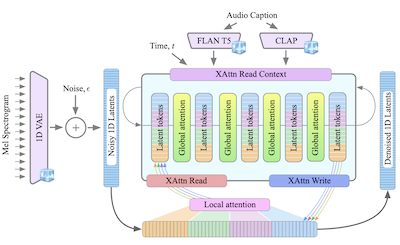
- Was ist GenAu? GenAu ist ein Transformer-basiertes latentes Diffusionsmodell für die Text-zu-Audio-Generierung, das eine FIT-artige Architektur mit lokaler und globaler Attention an die zeitliche Struktur von Audio anpasst.
- Warum ist Skalierung in dieser Arbeit wichtig? Die Arbeit zeigt, dass sich GenAu sowohl mit mehr synthetisch beschrifteten Daten als auch mit größerer Modellgröße verbessert, was wichtig ist, da frühere Generatoren für Umgebungsaudio oft ein schwaches oder inkonsistentes Skalierungsverhalten zeigten.
Wichtigste Beiträge
- Die Arbeit führt AutoReCap-XL ein, das darin als der größte Audio-Text-Datensatz für Umgebungsgeräusche beschrieben wird, mit 47 Millionen Clips und etwa 123,5 Tsd. Stunden Audio aus groß angelegten Videoquellen.
- Sie schlägt AutoCap vor, ein leistungsstarkes Audio-Beschriftungsmodell, das einen Q-Former und Metadaten nutzt, um die Qualität der Bildunterschriften zu verbessern, und einen CIDEr-Wert von 83,2 auf AudioCaps erreicht.
- Sie stellt GenAu vor, eine skalierbare, Transformer-basierte Text-zu-Audio-Diffusionsarchitektur, die einen 1D-VAE-Latentraum und FIT-inspirierte lokale/globale Attention für eine effiziente Audio-Generierung nutzt.
- Die Experimente zeigen deutliche Verbesserungen gegenüber vergleichbaren Text-zu-Audio-Baselines, einschließlich Gewinnen bei FAD, Inception Score und CLAP-Ausrichtung.
- Die Arbeit liefert ein ungewöhnlich vollständiges Skalierungsrezept für die Generierung von Umgebungsaudio, indem sie den Datensatz, die Beschriftungs-Pipeline und die Modellarchitektur gemeinsam verbessert, anstatt sie als separate Probleme zu behandeln.
Grenzen und Vorbehalte
- AutoCap wird auf AudioCaps feinabgestimmt, dessen Vokabular begrenzt ist, sodass sehr detaillierte oder ungewöhnliche Prompts weiterhin herausfordernd sein können; die Arbeit stellt dies als direkten Weg für zukünftige Verbesserungen des Beschriftungsmodells und des Datensatzes dar.
- AutoReCap-XL wird in erster Linie durch Experimente zur Audio-Generierung validiert, was ein starker erster Anwendungsfall ist und dabei Audio-Retrieval, Audio-Verständnis und Audio-Video-Aufgaben als vielversprechende Erweiterungen offenlässt.
- Die Pipeline zur Datensammlung stützt sich auf Transkripte, Metadaten und Filter-Heuristiken, aber gerade dies macht sie effizient genug, um weit über manuell beschriftete Audio-Datensätze für Umgebungsgeräusche hinaus zu skalieren.
- GenAu zielt auf Umgebungsgeräusche ab und nicht auf die Generierung von Sprache oder Musik, was der Arbeit einen fokussierten Beitrag verleiht und dabei verwandte Audiobereiche als natürliche Möglichkeiten zur Anpassung offenlässt.
- Das groß angelegte Training und ein Modell mit 1,25 Mrd. Parametern erfordern erhebliche Rechenleistung, aber die Ergebnisse sprechen stark dafür, dass sich diese Investition durch ein besseres Skalierungsverhalten bei der Generierung von Umgebungsaudio auszahlt.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein bedeutender systemischer Fortschritt für die Generierung von Umgebungsaudio lesen: Durch die Kombination eines riesigen neu beschrifteten Datensatzes, eines leistungsfähigeren Beschriftungsmodells und eines skalierbaren Transformer-Diffusionsgenerators liefert sie dem Feld ein praktisches Rezept zur Verbesserung der Text-zu-Audio-Qualität durch sowohl Daten- als auch Modellskalierung.