Taming Data and Transformers for Audio Generation
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu từ Rice University và Snap Inc. đã giải quyết một nút thắt cổ chai dai dẳng trong âm thanh môi trường do AI tạo ra — sự thiếu hụt dữ liệu huấn luyện lớn, được gán nhãn tốt và các mô hình không cải thiện khi chúng được mở rộng quy mô. Để giải quyết vấn đề dữ liệu, nhóm nghiên cứu đã phát triển một pipeline tự động khai thác các đoạn âm thanh môi trường từ các bộ dữ liệu video dựa trên YouTube hiện có bằng cách nhận diện các đoạn không có lời thoại hoặc bản chép âm nhạc, tránh được nhu cầu tải xuống và chạy các bộ phân loại đắt đỏ trên video thô. Kết quả là AutoReCap-XL, một bộ dữ liệu gồm 47 triệu đoạn âm thanh môi trường với mô tả văn bản, lớn hơn khoảng 75 lần so với những gì có sẵn trước đây. Để tạo ra các mô tả đó, họ đã xây dựng AutoCap, một mô hình chú thích âm thanh tích hợp một mô-đun Q-Former cùng với siêu dữ liệu trực quan như tiêu đề video và chú thích ở cấp độ khung hình, đạt điểm CIDEr là 83.2 trên benchmark AudioCaps tiêu chuẩn — một cải thiện 3.2% so với các phương pháp trước đó. Về phía tạo sinh, họ giới thiệu GenAu, một mô hình khuếch tán (diffusion) dựa trên transformer được mở rộng lên đến 1.25 tỷ tham số mượn kiến trúc "FIT" vốn ban đầu được thiết kế cho video, sử dụng các lớp chú ý cục bộ và toàn cục để tập trung tính toán vào các đoạn âm thanh giàu thông tin thay vì trải đều nó trên các phần im lặng hoặc dư thừa. So với các baseline tương đương, GenAu cải thiện Inception Score 11.1%, Fréchet Audio Distance 4.7%, và điểm CLAP về căn chỉnh văn bản 13.5%, và — không như các mô hình âm thanh lớn trước đây — tiếp tục cải thiện một cách nhất quán khi cả kích thước mô hình lẫn kích thước bộ dữ liệu tăng lên, gợi ý rằng lĩnh vực này cuối cùng có thể đã có một công thức để mở rộng việc tạo âm thanh môi trường theo cách mà việc tạo ảnh và video đã được mở rộng.
tóm tắt
Khả năng mở rộng của các trình tạo âm thanh môi trường (ambient sound) bị cản trở bởi sự khan hiếm dữ liệu, chất lượng chú thích không đủ, và khả năng mở rộng hạn chế trong kiến trúc mô hình. Công trình này giải quyết những thách thức đó bằng cách thúc đẩy việc mở rộng quy mô cả về dữ liệu lẫn mô hình. Đầu tiên, chúng tôi đề xuất một pipeline thu thập dữ liệu hiệu quả và có khả năng mở rộng được thiết kế riêng cho việc tạo âm thanh môi trường, tạo ra AutoReCap-XL, bộ dữ liệu âm thanh-văn bản môi trường lớn nhất với hơn 47 triệu đoạn clip. Để cung cấp các chú thích văn bản chất lượng cao, chúng tôi đề xuất AutoCap, một mô hình chú thích âm thanh tự động chất lượng cao. Bằng cách áp dụng một mô-đun Q-Former và tận dụng siêu dữ liệu âm thanh, AutoCap cải thiện đáng kể chất lượng chú thích, đạt điểm CIDEr là $83.2$, một cải thiện $3.2\%$ so với các mô hình chú thích trước đây. Cuối cùng, chúng tôi đề xuất GenAu, một kiến trúc tạo âm thanh dựa trên transformer có khả năng mở rộng mà chúng tôi mở rộng lên đến 1.25B tham số. Chúng tôi chứng minh lợi ích của nó từ việc mở rộng dữ liệu với các chú thích tổng hợp cũng như mở rộng kích thước mô hình. Khi so sánh với các trình tạo âm thanh baseline được huấn luyện ở quy mô kích thước và dữ liệu tương tự, GenAu đạt được những cải thiện đáng kể $4.7\%$ về điểm FAD, $11.1\%$ về IS, và $13.5\%$ về điểm CLAP. Mã nguồn, các checkpoint mô hình và bộ dữ liệu của chúng tôi đều được công khai.
chi tiết
trích dẫn
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- Bài báo này giải quyết vấn đề gì? Nó giải quyết các rào cản chính đối với việc tạo âm thanh môi trường có khả năng mở rộng: dữ liệu âm thanh-văn bản khan hiếm, chất lượng chú thích yếu, và các kiến trúc trình tạo không được hưởng lợi một cách đáng tin cậy từ việc mở rộng quy mô.
- AutoReCap-XL là gì? AutoReCap-XL là một bộ dữ liệu âm thanh-văn bản môi trường rất lớn với hơn 47 triệu đoạn clip được thu thập bằng cách lọc các đoạn video trực tuyến để tìm âm thanh không phải lời thoại, không phải âm nhạc và chú thích lại chúng một cách tự động.
- AutoCap là gì? AutoCap là một mô hình chú thích âm thanh tự động kết hợp các đặc trưng âm thanh, một Q-Former, giải mã BART, và siêu dữ liệu như tiêu đề video và chú thích trực quan để tạo ra các mô tả âm thanh chất lượng cao hơn.
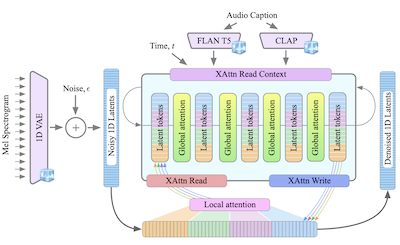
- GenAu là gì? GenAu là một mô hình khuếch tán tiềm ẩn (latent diffusion) dựa trên transformer cho việc tạo âm thanh từ văn bản, điều chỉnh một kiến trúc kiểu FIT với chú ý cục bộ và toàn cục cho cấu trúc thời gian của âm thanh.
- Tại sao việc mở rộng quy mô lại quan trọng trong công trình này? Bài báo cho thấy GenAu cải thiện với cả nhiều dữ liệu được chú thích tổng hợp hơn lẫn kích thước mô hình lớn hơn, điều này quan trọng vì các trình tạo âm thanh môi trường trước đây thường thể hiện hành vi mở rộng yếu hoặc không nhất quán.
Đóng góp chính
- Bài báo giới thiệu AutoReCap-XL, được mô tả là bộ dữ liệu âm thanh-văn bản môi trường lớn nhất trong công trình, với 47 triệu đoạn clip và khoảng 123.5k giờ âm thanh được lấy từ các nguồn video quy mô lớn.
- Bài báo đề xuất AutoCap, một bộ chú thích âm thanh mạnh mẽ sử dụng một Q-Former và siêu dữ liệu để cải thiện chất lượng chú thích, đạt điểm CIDEr là 83.2 trên AudioCaps.
- Bài báo trình bày GenAu, một kiến trúc khuếch tán âm thanh từ văn bản dựa trên transformer có khả năng mở rộng, sử dụng không gian tiềm ẩn 1D VAE và chú ý cục bộ/toàn cục lấy cảm hứng từ FIT để tạo âm thanh hiệu quả.
- Các thí nghiệm cho thấy những cải thiện rõ ràng so với các baseline âm thanh từ văn bản tương đương, bao gồm các cải thiện về FAD, Inception Score và căn chỉnh CLAP.
- Bài báo cung cấp một công thức mở rộng quy mô hoàn chỉnh khác thường cho việc tạo âm thanh môi trường bằng cách cải thiện đồng thời bộ dữ liệu, pipeline chú thích và kiến trúc mô hình thay vì coi chúng là những vấn đề riêng biệt.
Hạn chế và lưu ý
- AutoCap được tinh chỉnh trên AudioCaps, vốn có từ vựng hạn chế, nên các prompt rất chi tiết hoặc bất thường có thể vẫn còn thách thức; bài báo coi đây là một con đường trực tiếp để cải thiện bộ chú thích và bộ dữ liệu trong tương lai.
- AutoReCap-XL được kiểm chứng chủ yếu thông qua các thí nghiệm tạo âm thanh, đây là một trường hợp sử dụng đầu tiên mạnh mẽ trong khi vẫn để ngỏ truy hồi âm thanh, hiểu âm thanh và các tác vụ âm thanh-video như những mở rộng đầy hứa hẹn.
- Pipeline thu thập dữ liệu dựa vào bản chép lời, siêu dữ liệu và các phương pháp lọc kinh nghiệm, nhưng đây cũng chính là điều khiến nó đủ hiệu quả để mở rộng vượt xa các bộ dữ liệu âm thanh môi trường được chú thích thủ công.
- GenAu nhắm đến âm thanh môi trường thay vì tạo lời thoại hoặc âm nhạc, mang lại cho bài báo một đóng góp tập trung trong khi để ngỏ các miền âm thanh liên quan như những cơ hội tự nhiên để thích ứng.
- Việc huấn luyện quy mô lớn và một mô hình 1.25B tham số đòi hỏi tính toán đáng kể, nhưng các kết quả đưa ra một lập luận mạnh mẽ rằng khoản đầu tư này mang lại hành vi mở rộng tốt hơn cho việc tạo âm thanh môi trường.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một bước tiến lớn ở cấp độ hệ thống cho việc tạo âm thanh môi trường: bằng cách kết hợp một bộ dữ liệu được chú thích lại khổng lồ, một mô hình chú thích mạnh hơn, và một trình tạo khuếch tán transformer có khả năng mở rộng, nó mang lại cho lĩnh vực này một công thức thực tế để cải thiện chất lượng âm thanh từ văn bản thông qua việc mở rộng quy mô cả về dữ liệu lẫn mô hình.