Taming Data and Transformers for Audio Generation
Resumo do comunicado de imprensa
Pesquisadores da Rice University e da Snap Inc. enfrentaram um gargalo persistente no som ambiente gerado por IA — a escassez de dados de treinamento grandes e bem rotulados e os modelos que não melhoram à medida que crescem. Para resolver o problema dos dados, a equipe desenvolveu um pipeline automatizado que extrai clipes de áudio ambiente de conjuntos de dados de vídeo existentes baseados no YouTube, identificando trechos em que não há transcrição de fala ou música, contornando a necessidade de baixar e executar classificadores caros sobre o vídeo bruto. O resultado é o AutoReCap-XL, um conjunto de dados de 47 milhões de clipes de áudio ambiente com descrições textuais, cerca de 75 vezes maior do que o que estava disponível anteriormente. Para gerar essas descrições, eles construíram o AutoCap, um modelo de legendagem de áudio que incorpora um módulo Q-Former ao lado de metadados visuais como títulos de vídeo e legendas em nível de quadro, atingindo uma pontuação CIDEr de 83,2 no benchmark padrão AudioCaps — uma melhoria de 3,2% em relação aos métodos anteriores. No lado da geração, eles introduziram o GenAu, um modelo de difusão baseado em transformer escalado até 1,25 bilhão de parâmetros que toma emprestada uma arquitetura "FIT" originalmente projetada para vídeo, usando camadas de atenção local e global para concentrar a computação nos trechos de áudio informativos, em vez de distribuí-la uniformemente sobre porções silenciosas ou redundantes. Em comparação com baselines equivalentes, o GenAu melhorou o Inception Score em 11,1%, a Fréchet Audio Distance em 4,7% e a pontuação de alinhamento texto-áudio CLAP em 13,5% e — ao contrário de modelos de áudio grandes anteriores — continuou a melhorar de forma consistente à medida que tanto o tamanho do modelo quanto o do conjunto de dados aumentavam, sugerindo que a área pode finalmente ter uma receita para escalar a geração de som ambiente da mesma forma que a geração de imagem e vídeo já foi escalada.
resumo
A escalabilidade dos geradores de som ambiente é prejudicada pela escassez de dados, pela qualidade insuficiente das legendas e pela escalabilidade limitada da arquitetura do modelo. Este trabalho enfrenta esses desafios ao avançar tanto no escalonamento de dados quanto no de modelos. Primeiro, propomos um pipeline de coleta de dados eficiente e escalável, voltado para a geração de áudio ambiente, resultando no AutoReCap-XL, o maior conjunto de dados de áudio-texto ambiente, com mais de 47 milhões de clipes. Para fornecer anotações textuais de alta qualidade, propomos o AutoCap, um modelo de geração automática de legendas de áudio de alta qualidade. Ao adotar um módulo Q-Former e aproveitar os metadados de áudio, o AutoCap aprimora substancialmente a qualidade das legendas, atingindo uma pontuação CIDEr de $83.2$, uma melhoria de $3.2\%$ em relação a modelos de legendagem anteriores. Por fim, propomos o GenAu, uma arquitetura de geração de áudio escalável baseada em transformer que escalamos até 1,25B de parâmetros. Demonstramos seus benefícios tanto a partir do escalonamento de dados com legendas sintéticas quanto do escalonamento do tamanho do modelo. Quando comparado a geradores de áudio de baseline treinados em tamanho e escala de dados semelhantes, o GenAu obtém melhorias significativas de $4.7\%$ na pontuação FAD, $11.1\%$ no IS e $13.5\%$ na pontuação CLAP. Nosso código, checkpoints de modelo e conjunto de dados estão disponíveis publicamente.
detalhes
citação
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- Qual problema este artigo resolve? Ele aborda as principais barreiras para a geração escalável de som ambiente: dados de áudio-texto escassos, qualidade fraca das legendas e arquiteturas de geradores que não se beneficiaram de forma confiável do escalonamento.
- O que é o AutoReCap-XL? O AutoReCap-XL é um conjunto de dados de áudio-texto ambiente muito grande, com mais de 47 milhões de clipes, coletados ao filtrar trechos de vídeos on-line em busca de áudio sem fala e sem música e ao gerar legendas automaticamente para eles.
- O que é o AutoCap? O AutoCap é um modelo de legendagem automática de áudio que combina características de áudio, um Q-Former, decodificação BART e metadados como títulos de vídeo e legendas visuais para produzir descrições de áudio de maior qualidade.
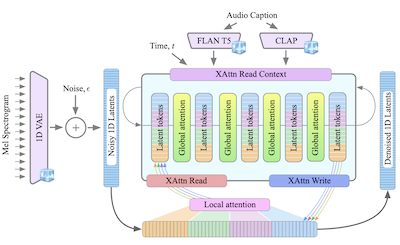
- O que é o GenAu? O GenAu é um modelo de difusão latente baseado em transformer para geração de texto para áudio que adapta uma arquitetura no estilo FIT, com atenção local e global, à estrutura temporal do áudio.
- Por que o escalonamento é importante neste trabalho? O artigo mostra que o GenAu melhora tanto com mais dados legendados sinteticamente quanto com um tamanho de modelo maior, o que é importante porque geradores de áudio ambiente anteriores frequentemente apresentavam comportamento de escalonamento fraco ou inconsistente.
Principais contribuições
- O artigo introduz o AutoReCap-XL, descrito como o maior conjunto de dados de áudio-texto ambiente do trabalho, com 47 milhões de clipes e cerca de 123,5 mil horas de áudio extraídas de fontes de vídeo de larga escala.
- Ele propõe o AutoCap, um robusto gerador de legendas de áudio que usa um Q-Former e metadados para melhorar a qualidade das legendas, atingindo uma pontuação CIDEr de 83,2 no AudioCaps.
- Ele apresenta o GenAu, uma arquitetura de difusão de texto para áudio escalável e baseada em transformer que usa um espaço latente de VAE 1D e atenção local/global inspirada no FIT para uma geração de áudio eficiente.
- Os experimentos mostram melhorias claras em relação a baselines de texto para áudio equivalentes, incluindo ganhos em FAD, Inception Score e alinhamento CLAP.
- O artigo fornece uma receita de escalonamento incomumente completa para a geração de áudio ambiente ao aprimorar conjuntamente o conjunto de dados, o pipeline de legendagem e a arquitetura do modelo, em vez de tratá-los como problemas separados.
Limitações e ressalvas
- O AutoCap é ajustado finamente no AudioCaps, cujo vocabulário é limitado, então prompts muito detalhados ou incomuns ainda podem ser desafiadores; o artigo enquadra isso como um caminho direto para futuras melhorias no gerador de legendas e no conjunto de dados.
- O AutoReCap-XL é validado principalmente por meio de experimentos de geração de áudio, que é um forte primeiro caso de uso, deixando a recuperação de áudio, a compreensão de áudio e as tarefas de áudio-vídeo como extensões promissoras.
- O pipeline de coleta de dados depende de transcrições, metadados e heurísticas de filtragem, mas é justamente isso que o torna eficiente o suficiente para escalar muito além dos conjuntos de dados de áudio ambiente legendados manualmente.
- O GenAu visa o som ambiente, e não a geração de fala ou música, conferindo ao artigo uma contribuição focada, ao mesmo tempo em que deixa domínios de áudio relacionados como oportunidades naturais de adaptação.
- O treinamento em larga escala e um modelo de 1,25B de parâmetros exigem uma computação considerável, mas os resultados apresentam um forte argumento de que esse investimento produz um melhor comportamento de escalonamento para a geração de áudio ambiente.
Como interpretar este resultado
Este artigo é mais bem compreendido como um grande avanço de nível sistêmico para a geração de áudio ambiente: ao combinar um conjunto de dados massivo com legendas regeneradas, um modelo de legendagem mais robusto e um gerador de difusão por transformer escalável, ele oferece à área uma receita prática para melhorar a qualidade de texto para áudio por meio do escalonamento tanto de dados quanto de modelo.