Taming Data and Transformers for Audio Generation
보도 자료 요약
라이스 대학교와 Snap Inc.의 연구진은 AI로 생성되는 주변음의 지속적인 병목, 즉 크고 잘 레이블링된 학습 데이터의 부족과 규모가 커져도 개선되지 못하는 모델의 문제를 다루었다. 데이터 문제를 해결하기 위해, 연구팀은 음성이나 음악 전사가 존재하지 않는 구간을 식별하여 기존 YouTube 기반 비디오 데이터셋에서 주변 오디오 클립을 채굴하는 자동화 파이프라인을 개발하였으며, 이는 원본 비디오를 내려받아 값비싼 분류기를 실행할 필요를 우회한다. 그 결과물이 텍스트 설명을 갖춘 4,700만 개의 주변 오디오 클립으로 구성된 데이터셋 AutoReCap-XL로, 이는 이전에 사용 가능했던 것보다 약 75배 더 크다. 그러한 설명을 생성하기 위해, 연구팀은 Q-Former 모듈과 더불어 비디오 제목 및 프레임 단위 캡션 같은 시각적 메타데이터를 통합한 오디오 캡셔닝 모델 AutoCap을 구축하였으며, 표준 AudioCaps 벤치마크에서 83.2의 CIDEr 점수에 도달하여 기존 방법 대비 3.2% 개선을 이루었다. 생성 측면에서는, 비디오를 위해 본래 설계된 "FIT" 아키텍처를 차용하여 1.25십억 파라미터까지 확장한 트랜스포머 기반 확산 모델 GenAu를 도입하였는데, 이는 지역 및 전역 어텐션 계층을 사용하여 무음이거나 중복된 부분에 계산을 균일하게 분산하는 대신 정보가 풍부한 오디오 구간에 집중한다. 비교 가능한 베이스라인과 대비하여, GenAu는 Inception Score를 11.1%, Fréchet Audio Distance를 4.7%, CLAP 텍스트 정렬 점수를 13.5% 개선하였으며, 이전의 대규모 오디오 모델과 달리 모델 크기와 데이터셋 크기가 모두 커짐에 따라 꾸준히 계속 개선되어, 이 분야가 마침내 이미지 및 비디오 생성이 이미 확장된 방식으로 주변음 생성을 확장하는 비결을 갖게 되었을 수 있음을 시사한다.
초록
주변음 생성기의 확장성은 데이터 부족, 불충분한 캡션 품질, 그리고 모델 아키텍처의 제한된 확장성으로 인해 저해된다. 본 연구는 데이터와 모델 양쪽의 확장을 발전시킴으로써 이러한 과제를 다룬다. 첫째, 우리는 주변 오디오 생성에 맞춘 효율적이고 확장 가능한 데이터셋 수집 파이프라인을 제안하며, 그 결과 4,700만 개가 넘는 클립을 가진 가장 큰 주변 오디오-텍스트 데이터셋인 AutoReCap-XL을 얻는다. 고품질의 텍스트 주석을 제공하기 위해, 우리는 고품질 자동 오디오 캡셔닝 모델인 AutoCap을 제안한다. Q-Former 모듈을 채택하고 오디오 메타데이터를 활용함으로써, AutoCap은 캡션 품질을 크게 향상시켜 이전 캡셔닝 모델 대비 $3.2\%$ 개선된 $83.2$의 CIDEr 점수에 도달한다. 마지막으로, 우리는 1.25B 파라미터까지 확장한 확장 가능한 트랜스포머 기반 오디오 생성 아키텍처인 GenAu를 제안한다. 우리는 합성 캡션을 통한 데이터 확장과 모델 크기 확장 모두로부터의 이점을 입증한다. 유사한 크기와 데이터 규모로 학습된 베이스라인 오디오 생성기와 비교했을 때, GenAu는 FAD 점수에서 $4.7\%$, IS에서 $11.1\%$, CLAP 점수에서 $13.5\%$의 상당한 개선을 얻는다. 우리의 코드, 모델 체크포인트, 데이터셋은 공개되어 있다.
세부 정보
인용
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- 이 논문은 어떤 문제를 해결하는가? 이 논문은 확장 가능한 주변음 생성의 주요 장벽인 부족한 오디오-텍스트 데이터, 약한 캡션 품질, 그리고 확장으로부터 신뢰성 있게 이점을 얻지 못한 생성기 아키텍처를 다룬다.
- AutoReCap-XL이란 무엇인가? AutoReCap-XL은 온라인 비디오 구간을 음성이 아니고 음악이 아닌 오디오에 대해 필터링하고 자동으로 재캡셔닝하여 수집한 4,700만 개가 넘는 클립을 가진 매우 큰 주변 오디오-텍스트 데이터셋이다.
- AutoCap이란 무엇인가? AutoCap은 오디오 특징, Q-Former, BART 디코딩, 그리고 비디오 제목과 시각적 캡션 같은 메타데이터를 결합하여 더 높은 품질의 오디오 설명을 생성하는 자동 오디오 캡셔닝 모델이다.
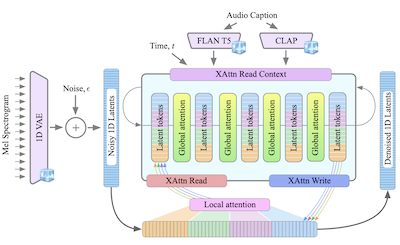
- GenAu란 무엇인가? GenAu는 FIT 스타일 아키텍처를 지역 및 전역 어텐션과 함께 오디오의 시간적 구조에 맞게 적응시킨, 텍스트-오디오 생성을 위한 트랜스포머 기반 잠재 확산 모델이다.
- 이 연구에서 확장은 왜 중요한가? 논문은 GenAu가 더 많은 합성 캡션 데이터와 더 큰 모델 크기 모두로부터 개선됨을 보이는데, 이는 이전의 주변 오디오 생성기들이 종종 약하거나 일관되지 않은 확장 거동을 보였기 때문에 중요하다.
주요 기여
- 논문은 대규모 비디오 소스에서 가져온 4,700만 개의 클립과 약 123.5k 시간의 오디오를 갖춘, 이 연구에서 가장 큰 주변 오디오-텍스트 데이터셋으로 기술되는 AutoReCap-XL을 도입한다.
- 논문은 Q-Former와 메타데이터를 사용하여 캡션 품질을 개선하고 AudioCaps에서 83.2의 CIDEr 점수에 도달하는 강력한 오디오 캡셔너 AutoCap을 제안한다.
- 논문은 효율적인 오디오 생성을 위해 1D VAE 잠재 공간과 FIT에서 영감을 받은 지역/전역 어텐션을 사용하는 확장 가능한 트랜스포머 기반 텍스트-오디오 확산 아키텍처 GenAu를 제시한다.
- 실험은 FAD, Inception Score, CLAP 정렬에서의 향상을 포함하여 비교 가능한 텍스트-오디오 베이스라인 대비 명확한 개선을 보인다.
- 논문은 데이터셋, 캡셔닝 파이프라인, 모델 아키텍처를 별개의 문제로 다루는 대신 함께 개선함으로써, 주변 오디오 생성을 위한 이례적으로 완결적인 확장 비결을 제공한다.
한계 및 유의 사항
- AutoCap은 어휘가 제한된 AudioCaps에 대해 파인튜닝되므로, 매우 상세하거나 특이한 프롬프트는 여전히 어려울 수 있다. 논문은 이를 향후 캡셔너 및 데이터셋 개선을 위한 직접적인 경로로 제시한다.
- AutoReCap-XL은 주로 오디오 생성 실험을 통해 검증되는데, 이는 강력한 첫 사용 사례인 동시에 오디오 검색, 오디오 이해, 오디오-비디오 과제를 유망한 확장으로 남겨둔다.
- 데이터 수집 파이프라인은 전사, 메타데이터, 필터링 휴리스틱에 의존하지만, 바로 이 점이 수동으로 캡셔닝된 주변 오디오 데이터셋을 훨씬 넘어 확장할 만큼 효율적으로 만들어 준다.
- GenAu는 음성이나 음악 생성이 아니라 주변음을 대상으로 하여, 논문에 초점 있는 기여를 부여하는 동시에 관련 오디오 도메인을 적응을 위한 자연스러운 기회로 남겨둔다.
- 대규모 학습과 1.25B 파라미터 모델은 상당한 계산 자원을 요구하지만, 그 결과는 이러한 투자가 주변 오디오 생성에 더 나은 확장 거동을 가져온다는 강력한 근거를 제시한다.
이 결과를 읽는 방법
이 논문은 주변 오디오 생성을 위한 주요 시스템 수준의 발전으로 읽는 것이 가장 좋다. 대규모 재캡셔닝 데이터셋, 더 강력한 캡셔닝 모델, 확장 가능한 트랜스포머 확산 생성기를 결합함으로써, 이 분야에 데이터와 모델 확장 모두를 통해 텍스트-오디오 품질을 개선하는 실용적인 비결을 제공한다.