Taming Data and Transformers for Audio Generation
プレスリリース要約
Rice大学とSnap Inc.の研究者らは、AIによる環境音生成における根強いボトルネック、すなわち大規模で適切にラベル付けされた学習データの不足と、規模が大きくなっても改善しないモデルという問題に取り組みました。データ問題に対処するため、チームは、音声や音楽の文字起こしが存在しないセグメントを特定することで、既存のYouTubeベースの動画データセットから環境音オーディオクリップを採掘する自動パイプラインを開発し、生の動画をダウンロードして高コストな分類器を実行する必要を回避しました。その結果が、テキスト記述を伴う4,700万の環境音オーディオクリップからなるデータセットAutoReCap-XLであり、これは以前利用可能だったものの約75倍の規模です。それらの記述を生成するために、彼らはAutoCapを構築しました。これは、動画タイトルやフレームレベルのキャプションといった視覚的メタデータとともにQ-Formerモジュールを組み込んだオーディオキャプショニングモデルで、標準のAudioCapsベンチマークでCIDErスコア83.2に達し、これは従来手法と比べて3.2%の改善です。生成側では、彼らはGenAuを導入しました。これは、元々動画向けに設計された「FIT」アーキテクチャを借用し、ローカルおよびグローバルなアテンション層を使用して、無音または冗長な部分に計算を均一に分散させるのではなく、情報量の多いオーディオセグメントに計算を集中させる、12.5億パラメータまでスケールアップしたTransformerベースの拡散モデルです。同等のベースラインと比較して、GenAuはInception Scoreを11.1%、Fréchet Audio Distanceを4.7%、CLAPテキスト整合スコアを13.5%改善し、そして従来の大規模オーディオモデルとは異なり、モデルサイズとデータセットサイズの両方が増加するにつれて一貫して改善し続けました。これは、画像や動画の生成がすでにスケールされてきたのと同じように、環境音生成をスケールさせるためのレシピがこの分野でついに得られた可能性を示唆しています。
要旨
環境音生成器のスケーラビリティは、データの不足、キャプション品質の不十分さ、そしてモデルアーキテクチャにおける限定的なスケーラビリティによって妨げられています。本研究は、データとモデルの両方のスケーリングを進めることで、これらの課題に対処します。まず、環境音生成に特化した効率的でスケーラブルなデータセット収集パイプラインを提案し、その結果、4,700万を超えるクリップを持つ最大の環境音オーディオテキストデータセットであるAutoReCap-XLが得られました。高品質なテキストアノテーションを提供するために、私たちは高品質な自動オーディオキャプショニングモデルであるAutoCapを提案します。Q-Formerモジュールを採用しオーディオメタデータを活用することで、AutoCapはキャプション品質を大幅に向上させ、CIDErスコア$83.2$に達し、これは従来のキャプショニングモデルと比べて$3.2\%$の改善です。最後に、私たちは1.25Bパラメータまでスケールアップした、スケーラブルなTransformerベースのオーディオ生成アーキテクチャであるGenAuを提案します。私たちは、合成キャプションを用いたデータスケーリングおよびモデルサイズのスケーリングによる利点を実証します。同様のサイズとデータ規模で学習させたベースラインのオーディオ生成器と比較すると、GenAuはFADスコアで$4.7\%$、ISで$11.1\%$、CLAPスコアで$13.5\%$の大幅な改善を達成します。私たちのコード、モデルチェックポイント、データセットは公開されています。
詳細
引用
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- 本論文はどのような問題を解決するのか。本論文は、スケーラブルな環境音生成に対する主な障壁、すなわちオーディオテキストデータの不足、弱いキャプション品質、そしてスケーリングから確実に恩恵を受けてこなかった生成器アーキテクチャに対処します。
- AutoReCap-XLとは何か。AutoReCap-XLは、オンライン動画セグメントを音声・音楽以外のオーディオでフィルタリングし、それらを自動的に再キャプショニングすることで収集された、4,700万を超えるクリップを持つ非常に大規模な環境音オーディオテキストデータセットです。
- AutoCapとは何か。AutoCapは、オーディオ特徴量、Q-Former、BARTデコーディング、そして動画タイトルや視覚的キャプションといったメタデータを組み合わせて、より高品質なオーディオ記述を生成する自動オーディオキャプショニングモデルです。
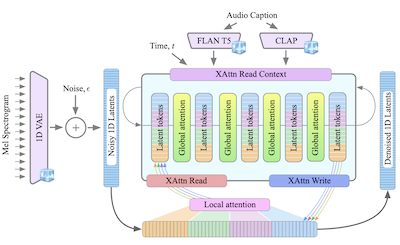
- GenAuとは何か。GenAuは、ローカルおよびグローバルなアテンションを持つFITスタイルのアーキテクチャをオーディオの時間的構造に適応させた、テキストからオーディオへの生成のためのTransformerベースの潜在拡散モデルです。
- 本研究においてスケーリングはなぜ重要なのか。論文は、GenAuがより多くの合成キャプション付きデータとより大きなモデルサイズの両方によって改善することを示しています。これは、初期の環境音生成器がしばしば弱い、または一貫性のないスケーリング挙動を示していたため重要です。
主な貢献
- 本論文は、大規模な動画ソースから取得した4,700万のクリップと約123.5k時間のオーディオを持つ、本研究で最大の環境音オーディオテキストデータセットと説明されるAutoReCap-XLを導入します。
- 本論文は、Q-Formerとメタデータを使用してキャプション品質を向上させ、AudioCapsでCIDErスコア83.2に達する強力なオーディオキャプショナーであるAutoCapを提案します。
- 本論文は、効率的なオーディオ生成のために1D VAE潜在空間とFITに着想を得たローカル/グローバルアテンションを使用する、スケーラブルなTransformerベースのテキストからオーディオへの拡散アーキテクチャであるGenAuを提示します。
- 実験は、FAD、Inception Score、CLAP整合性における向上を含め、同等のテキストからオーディオへのベースラインに対する明確な改善を示しています。
- 本論文は、データセット、キャプショニングパイプライン、モデルアーキテクチャを別個の問題として扱うのではなく一体的に改善することで、環境音生成のための異例なほど完全なスケーリングレシピを提供します。
限界と注意点
- AutoCapは、語彙が限定的なAudioCapsでファインチューニングされているため、非常に詳細または珍しいプロンプトは依然として困難な場合があります。論文はこれを、今後のキャプショナーおよびデータセット改善への直接的な道筋として位置づけています。
- AutoReCap-XLは主にオーディオ生成実験を通じて検証されており、これは強力な最初のユースケースである一方、オーディオ検索、オーディオ理解、オーディオ動画タスクは有望な拡張として残されています。
- データ収集パイプラインは文字起こし、メタデータ、フィルタリングのヒューリスティックに依存していますが、これはまた、手動でキャプションを付けた環境音オーディオデータセットをはるかに超えてスケールできるほど効率的にしている要因でもあります。
- GenAuは音声や音楽の生成ではなく環境音を対象としており、論文に焦点を絞った貢献を与える一方、関連するオーディオドメインを適応のための自然な機会として残しています。
- 大規模な学習と12.5億パラメータのモデルには相応の計算量が必要ですが、結果は、この投資が環境音生成においてより優れたスケーリング挙動をもたらすという強力な根拠を示しています。
この結果の読み解き方
本論文は、環境音生成のためのシステムレベルにおける大きな進歩として読むのが最も適切です。巨大な再キャプショニングされたデータセット、より強力なキャプショニングモデル、そしてスケーラブルなTransformer拡散生成器を組み合わせることで、本論文は、データとモデルの両方のスケーリングを通じてテキストからオーディオへの品質を向上させるための実用的なレシピをこの分野に提供します。