Instance-level Image Retrieval using Reranking Transformers
Zusammenfassung der Pressemitteilung
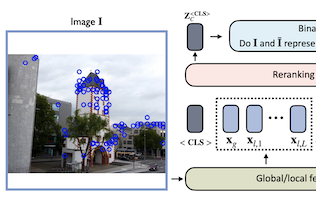
Forscher der University of Virginia, von eBay und der Rice University haben ein leichtgewichtiges neuronales Netzmodell namens Reranking Transformer, kurz RRT, entwickelt, das die Genauigkeit von Bildsuchsystemen verbessert, die versuchen, bestimmte Objekte oder Sehenswürdigkeiten statt grober Kategorien zu identifizieren. Das Problem, das das Team angegangen ist, besteht in einem zweistufigen Prozess, der im Image Retrieval üblich ist: Ein erster Durchgang verwendet einen kompakten globalen Bilddeskriptor, um eine engere Auswahl von Kandidatentreffern hervorzuholen, und ein zweiter Durchgang verfeinert diese Liste anhand detaillierterer lokaler Merkmale — ein Schritt, der traditionell durch geometrische Verifikation gehandhabt wird, eine rechenintensive Technik, die zu schätzen versucht, wie ein Bild geometrisch verzerrt werden kann, um zu einem anderen zu passen. Die Forscher ersetzten diesen zweiten Schritt durch ein kleines, auf einem Transformer basierendes Modell, das sich der aufmerksamkeitsbasierten Architektur bedient, die jüngste Fortschritte in der Verarbeitung natürlicher Sprache vorangetrieben hat, und trainierten es, direkt vorherzusagen, ob zwei Bilder dasselbe Objekt oder dieselbe Szene zeigen. Mit nur etwa 2,2 Millionen Parametern — rund 9 Prozent der Größe eines Standard-ResNet50-Backbones — und unter Verwendung von nur halb so vielen lokalen Merkmalsdeskriptoren wie die geometrische Verifikation übertraf RRT dennoch die geometrische Verifikation und andere konkurrierende Ansätze auf Standard-Benchmarks, darunter die Datensätze Revisited Oxford und Paris sowie Google Landmarks v2. Ein wesentlicher praktischer Vorteil besteht darin, dass das Reranking einer gesamten engeren Auswahl von 100 Kandidatenbildern nur einen einzigen Vorwärtsdurchlauf durch das Netz erfordert. Die Forscher zeigten außerdem, dass RRT im Gegensatz zur geometrischen Verifikation gemeinsam mit dem zugrunde liegenden Merkmalsextraktor trainiert werden kann, sodass die beiden Komponenten zusammen optimiert werden können und weitere Genauigkeitsgewinne erzielt werden, eine Fähigkeit, die sie auf dem Stanford Online Products-Datensatz demonstrierten.
Zusammenfassung
Instance-Level Image Retrieval ist die Aufgabe, in einer großen Datenbank nach Bildern zu suchen, die zu einem Objekt in einem Anfragebild passen. Um diese Aufgabe zu bewältigen, stützen sich Systeme in der Regel auf einen Retrieval-Schritt, der globale Bilddeskriptoren verwendet, sowie auf einen anschließenden Schritt, der domänenspezifische Verfeinerungen oder ein Reranking durchführt, indem er Operationen wie die geometrische Verifikation auf der Grundlage lokaler Merkmale nutzt. In dieser Arbeit schlagen wir Reranking Transformers (RRTs) als allgemeines Modell vor, um sowohl lokale als auch globale Merkmale einzubeziehen, um die übereinstimmenden Bilder auf überwachte Weise neu zu sortieren und so den relativ aufwendigen Prozess der geometrischen Verifikation zu ersetzen. RRTs sind leichtgewichtig und lassen sich einfach parallelisieren, sodass das Reranking einer Menge der besten übereinstimmenden Ergebnisse in einem einzigen Vorwärtsdurchlauf durchgeführt werden kann. Wir führen umfangreiche Experimente auf den Datensätzen Revisited Oxford und Paris sowie auf dem Google Landmarks v2-Datensatz durch und zeigen, dass RRTs frühere Reranking-Ansätze übertreffen, während sie deutlich weniger lokale Deskriptoren verwenden. Darüber hinaus zeigen wir, dass RRTs im Gegensatz zu bestehenden Ansätzen gemeinsam mit dem Merkmalsextraktor optimiert werden können, was zu auf nachgelagerte Aufgaben zugeschnittenen Merkmalsrepräsentationen und weiteren Genauigkeitsverbesserungen führen kann. Der Code und die trainierten Modelle sind öffentlich verfügbar unter https://github.com/uvavision/RerankingTransformer.
Details
Zitation
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}