Instance-level Image Retrieval using Reranking Transformers
Tóm tắt thông cáo báo chí
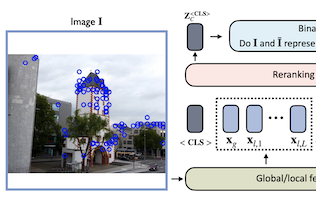
Các nhà nghiên cứu từ University of Virginia, eBay, và Rice University đã phát triển một mô hình mạng nơ-ron nhẹ gọi là Reranking Transformer, hay RRT, cải thiện độ chính xác của các hệ thống tìm kiếm ảnh cố gắng nhận diện các đối tượng hoặc địa danh cụ thể thay vì các danh mục rộng. Vấn đề mà nhóm giải quyết là một quy trình hai bước phổ biến trong truy hồi ảnh: một lượt đầu tiên sử dụng một mô tả ảnh toàn cục gọn nhẹ để rút ra một danh sách ngắn các ứng viên khớp, và một lượt thứ hai tinh chỉnh danh sách đó bằng các đặc trưng cục bộ chi tiết hơn — một bước theo truyền thống được xử lý bằng xác minh hình học, một kỹ thuật tốn kém về mặt tính toán cố gắng ước lượng cách một ảnh có thể được biến dạng hình học để khớp với một ảnh khác. Các nhà nghiên cứu đã thay thế bước thứ hai đó bằng một mô hình nhỏ dựa trên transformer, mượn kiến trúc dựa trên cơ chế chú ý vốn đã thúc đẩy những tiến bộ gần đây trong xử lý ngôn ngữ tự nhiên, và huấn luyện nó để trực tiếp dự đoán liệu hai ảnh có thể hiện cùng một đối tượng hoặc cảnh hay không. Với chỉ khoảng 2.2 triệu tham số — khoảng 9 phần trăm kích thước của một backbone ResNet50 tiêu chuẩn — và chỉ đòi hỏi một nửa số lượng mô tả đặc trưng cục bộ so với xác minh hình học, RRT vẫn vượt trội hơn xác minh hình học và các cách tiếp cận cạnh tranh khác trên các benchmark tiêu chuẩn bao gồm các bộ dữ liệu Revisited Oxford và Paris và Google Landmarks v2. Một lợi thế thực tiễn then chốt là việc xếp hạng lại toàn bộ một danh sách ngắn gồm 100 ảnh ứng viên chỉ mất một lượt truyền xuôi duy nhất qua mạng. Các nhà nghiên cứu cũng cho thấy rằng, không giống xác minh hình học, RRT có thể được huấn luyện cùng nhau với bộ trích xuất đặc trưng nền tảng, cho phép hai thành phần được tối ưu hóa cùng nhau và mang lại những lợi ích độ chính xác hơn nữa, một khả năng mà họ đã chứng minh trên bộ dữ liệu Stanford Online Products.
tóm tắt
Truy hồi ảnh ở cấp độ thực thể là tác vụ tìm kiếm trong một cơ sở dữ liệu lớn các ảnh khớp với một đối tượng trong một ảnh truy vấn. Để giải quyết tác vụ này, các hệ thống thường dựa vào một bước truy hồi sử dụng các mô tả ảnh toàn cục, và một bước tiếp theo thực hiện các tinh chỉnh đặc thù theo lĩnh vực hoặc xếp hạng lại bằng cách tận dụng các thao tác như xác minh hình học dựa trên các đặc trưng cục bộ. Trong công trình này, chúng tôi đề xuất Reranking Transformers (RRTs) như một mô hình tổng quát để kết hợp cả các đặc trưng cục bộ và toàn cục nhằm xếp hạng lại các ảnh khớp theo một cách có giám sát và do đó thay thế cho quá trình xác minh hình học tương đối tốn kém. RRTs nhẹ và có thể dễ dàng song song hóa để việc xếp hạng lại một tập các kết quả khớp hàng đầu có thể được thực hiện trong một lượt truyền xuôi duy nhất. Chúng tôi thực hiện các thí nghiệm rộng rãi trên các bộ dữ liệu Revisited Oxford và Paris, và bộ dữ liệu Google Landmarks v2, cho thấy RRTs vượt trội hơn các cách tiếp cận xếp hạng lại trước đây trong khi sử dụng ít mô tả cục bộ hơn nhiều. Hơn nữa, chúng tôi chứng minh rằng, không giống các cách tiếp cận hiện có, RRTs có thể được tối ưu hóa cùng nhau với bộ trích xuất đặc trưng, điều này có thể dẫn đến các biểu diễn đặc trưng được thiết kế riêng cho các tác vụ hạ nguồn và những cải thiện độ chính xác hơn nữa. Mã và các mô hình đã huấn luyện được công bố công khai tại https://github.com/uvavision/RerankingTransformer.
chi tiết
trích dẫn
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}