プレスリリース要約
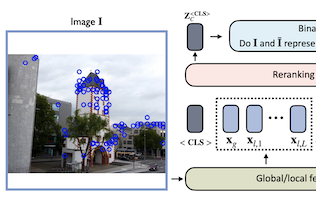
University of Virginia、eBay、Rice Universityの研究者らは、広いカテゴリではなく特定の物体やランドマークを識別しようとする画像検索システムの精度を向上させる、再ランキングTransformer(Reranking Transformer、RRT)と呼ばれる軽量なニューラルネットワークモデルを開発しました。研究チームが取り組んだ問題は、画像検索でよく見られる2段階のプロセスです。最初のパスではコンパクトなグローバル画像記述子を用いて候補一致のショートリストを引き出し、2番目のパスではより詳細な局所特徴を用いてそのリストを絞り込みます。後者は伝統的に幾何学的検証によって処理されてきました。これは、ある画像が別の画像に一致するようにどのように幾何学的に変形できるかを推定しようとする、計算コストの高い技術です。研究者らはその2番目のステップを、自然言語処理における近年の進歩を牽引してきた注意機構ベースのアーキテクチャを借用した小さなTransformerベースのモデルに置き換え、2つの画像が同じ物体やシーンを示しているかどうかを直接予測するように学習させました。約220万のパラメータ、すなわち標準的なResNet50バックボーンのおよそ9パーセントの大きさで、幾何学的検証の半分の数の局所特徴記述子しか必要としないにもかかわらず、RRTはRevisited OxfordおよびParisデータセットやGoogle Landmarks v2を含む標準ベンチマークで、幾何学的検証や他の競合アプローチを上回りました。重要な実用上の利点は、100枚の候補画像からなるショートリスト全体の再ランキングが、ネットワークを通る単一の順伝播だけで済むことです。研究者らはまた、幾何学的検証とは異なり、RRTが基盤となる特徴抽出器と共同で学習でき、その2つのコンポーネントをともに最適化してさらなる精度向上をもたらせることも示し、その能力をStanford Online Productsデータセットで実証しました。
要旨
インスタンスレベル画像検索は、クエリ画像内の物体に一致する画像を大規模なデータベースから検索するタスクです。このタスクに対処するために、システムは通常、グローバル画像記述子を用いる検索ステップと、それに続く、局所特徴に基づく幾何学的検証などの操作を活用してドメイン固有の絞り込みや再ランキングを行うステップに依存します。本研究では、局所特徴とグローバル特徴の両方を組み込んで一致画像を教師ありの方法で再ランキングし、それによって比較的高コストな幾何学的検証のプロセスを置き換える汎用モデルとして、再ランキングTransformer(Reranking Transformers、RRT)を提案します。RRTは軽量で容易に並列化できるため、上位の一致結果の集合の再ランキングを単一の順伝播で実行できます。我々はRevisited OxfordおよびParisデータセット、ならびにGoogle Landmarks v2データセットで広範な実験を行い、RRTがはるかに少ない局所記述子を用いながら従来の再ランキングアプローチを上回ることを示します。さらに、既存のアプローチとは異なり、RRTは特徴抽出器と共同で最適化でき、これが下流タスクに合わせた特徴表現とさらなる精度向上につながりうることを実証します。コードと学習済みモデルはhttps://github.com/uvavision/RerankingTransformer で公開されています。
詳細
引用
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}