新闻稿摘要
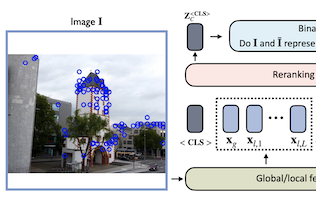
来自弗吉尼亚大学、eBay 和莱斯大学的研究人员开发了一种名为重排序 Transformer(Reranking Transformer,简称 RRT)的轻量级神经网络模型,它提升了那些试图识别特定物体或地标(而非宽泛类别)的图像搜索系统的准确率。该团队所应对的问题是图像检索中常见的两步流程:第一步使用紧凑的全局图像描述子拉取一份候选匹配的候选名单,第二步则使用更细致的局部特征来精炼这份名单——这一步传统上由几何验证(geometric verification)处理,这是一种计算昂贵的技术,它试图估计一幅图像如何可以经几何形变以匹配另一幅图像。研究人员用一个小型的基于 Transformer 的模型取代了第二步,借鉴了推动自然语言处理近期进展的基于注意力的架构,并训练它直接预测两幅图像是否展示同一物体或场景。RRT 仅有约 220 万参数——大约是标准 ResNet50 主干规模的 9%——并且只需要几何验证一半数量的局部特征描述子,却依然在包括 Revisited Oxford、Paris 数据集和 Google Landmarks v2 在内的标准基准上优于几何验证及其他竞争方法。一个关键的实际优势是,对包含 100 个候选图像的整份候选名单进行重排序只需通过该网络一次前向传播。研究人员还表明,与几何验证不同,RRT 可以与底层特征提取器联合训练,从而使两个组件一同优化并带来进一步的准确率提升,他们在 Stanford Online Products 数据集上演示了这一能力。
摘要
实例级图像检索(instance-level image retrieval)的任务是在大型数据库中搜索与查询图像中某个物体相匹配的图像。为完成这一任务,系统通常依赖于一个使用全局图像描述子的检索步骤,以及一个后续步骤——后者通过利用诸如基于局部特征的几何验证(geometric verification)等操作来执行特定领域的精炼或重排序。在本工作中,我们提出了重排序 Transformer(Reranking Transformers,RRTs),作为一个同时纳入局部和全局特征、以有监督方式对匹配图像进行重排序的通用模型,从而替代相对昂贵的几何验证过程。RRTs 是轻量级的,并且易于并行化,因而对一组排名靠前的匹配结果进行重排序可以在单次前向传播中完成。我们在 Revisited Oxford 和 Paris 数据集以及 Google Landmarks v2 数据集上进行了大量实验,表明 RRTs 在使用少得多的局部描述子的同时优于以往的重排序方法。此外,我们证明,与现有方法不同,RRTs 可以与特征提取器联合优化,这可以带来为下游任务量身定制的特征表示以及进一步的准确率提升。代码和训练好的模型已在 https://github.com/uvavision/RerankingTransformer 公开。
详情
引用
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}