Instance-level Image Retrieval using Reranking Transformers
Resumo do comunicado de imprensa
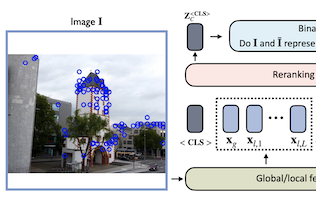
Pesquisadores da University of Virginia, da eBay e da Rice University desenvolveram um modelo leve de rede neural chamado Reranking Transformer, ou RRT, que melhora a acurácia de sistemas de busca de imagens que tentam identificar objetos ou pontos de referência específicos em vez de categorias amplas. O problema que a equipe enfrentou é um processo de duas etapas comum na recuperação de imagens: uma primeira passagem usa um descritor global compacto de imagem para gerar uma lista reduzida de candidatos correspondentes, e uma segunda passagem refina essa lista usando características locais mais detalhadas — uma etapa tradicionalmente tratada pela verificação geométrica, uma técnica computacionalmente custosa que tenta estimar como uma imagem pode ser deformada geometricamente para corresponder a outra. Os pesquisadores substituíram essa segunda etapa por um pequeno modelo baseado em transformer, tomando emprestada a arquitetura baseada em atenção que impulsionou avanços recentes no processamento de linguagem natural, e o treinaram para prever diretamente se duas imagens mostram o mesmo objeto ou cena. Com apenas cerca de 2,2 milhões de parâmetros — aproximadamente 9 por cento do tamanho de um backbone ResNet50 padrão — e exigindo apenas metade dos descritores de características locais da verificação geométrica, o RRT, ainda assim, superou a verificação geométrica e outras abordagens concorrentes em benchmarks padrão, incluindo os conjuntos de dados Revisited Oxford e Paris e o Google Landmarks v2. Uma vantagem prática fundamental é que reordenar uma lista inteira de 100 imagens candidatas requer apenas uma única passagem direta pela rede. Os pesquisadores também mostraram que, diferentemente da verificação geométrica, o RRT pode ser treinado conjuntamente com o extrator de características subjacente, permitindo que os dois componentes sejam otimizados juntos e gerando ganhos adicionais de acurácia, uma capacidade que demonstraram no conjunto de dados Stanford Online Products.
resumo
A recuperação de imagens em nível de instância é a tarefa de buscar, em um grande banco de dados, imagens que correspondam a um objeto em uma imagem de consulta. Para enfrentar essa tarefa, os sistemas geralmente se baseiam em uma etapa de recuperação que usa descritores globais de imagem e em uma etapa subsequente que realiza refinamentos específicos do domínio ou reordenação (reranking), aproveitando operações como a verificação geométrica baseada em características locais. Neste trabalho, propomos os Reranking Transformers (RRTs) como um modelo geral para incorporar características locais e globais a fim de reordenar as imagens correspondentes de forma supervisionada e, assim, substituir o processo relativamente custoso de verificação geométrica. Os RRTs são leves e podem ser facilmente paralelizados, de modo que a reordenação de um conjunto de melhores resultados correspondentes pode ser realizada em um único forward-pass. Realizamos experimentos extensos nos conjuntos de dados Revisited Oxford e Paris e no conjunto de dados Google Landmarks v2, mostrando que os RRTs superam abordagens anteriores de reordenação usando muito menos descritores locais. Além disso, demonstramos que, diferentemente das abordagens existentes, os RRTs podem ser otimizados conjuntamente com o extrator de características, o que pode levar a representações de características adaptadas a tarefas downstream e a melhorias adicionais de acurácia. O código e os modelos treinados estão disponíveis publicamente em https://github.com/uvavision/RerankingTransformer.
detalhes
citação
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}