ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Zusammenfassung der Pressemitteilung
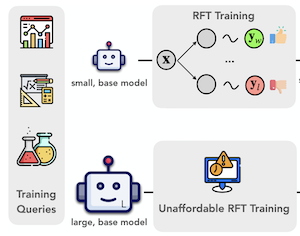
Forschende der Rice University, der University of Illinois Urbana-Champaign und der University of Virginia haben eine Methode namens ProxyThinker entwickelt, die es großen Vision-Language-Modellen ermöglicht, zur Testzeit sorgfältiger zu schlussfolgern – ohne zusätzliches Training. Das Problem, das sie lösen wollten, ist ein praktisches: Großen KI-Modellen beizubringen, „langsamer zu werden“ und komplexe visuelle Probleme Schritt für Schritt durchzuarbeiten, erfordert typischerweise aufwendiges Reinforcement Fine-Tuning, ein Prozess, der enorme Rechenressourcen verlangt und nur selten auf Modelle mit mehr als sieben Milliarden Parametern angewandt wurde. ProxyThinker umgeht diese Kosten vollständig, indem es während der Inferenz zwei kleine Begleitmodelle neben dem großen Modell laufen lässt – eines, das bereits darauf feinjustiert wurde, sorgfältig zu schlussfolgern, und eines, das es nicht wurde – und die Differenz zwischen ihren Ausgabeverteilungen nutzt, um die Token-für-Token-Generierung des großen Modells in Richtung eines überlegteren, selbstprüfenden Schlussfolgerns zu lenken. In der Praxis bedeutet dies, dass das große Modell beginnt, Verhaltensweisen wie Zurückverfolgen, Selbstverifikation und mehrstufige Korrektur zu zeigen, die es andernfalls nur selten hervorbrächte. Bei der Erprobung des Ansatzes auf standardmäßigen visuellen Mathematik- und multidisziplinären Benchmarks stellte das Team fest, dass ein Basismodell mit 32 Milliarden Parametern, gesteuert von einem schwachen Reasoning-Experten mit 7 Milliarden Parametern, die Leistung eines dedizierten Modells mit 32 Milliarden Parametern erreichen oder leicht übertreffen konnte, das vollständig mit Reinforcement Learning feinjustiert worden war. Das Team entwickelte außerdem eine parallelisierte Implementierung auf Basis des vLLM-Inferenz-Frameworks, die etwa 38-mal schneller läuft als frühere Steuerungsmethoden zur Decodierungszeit und die Wanduhr-Inferenzzeit nahe an die bloße Ausführung eines einzelnen großen Modells heranführt. Die Arbeit ist von Bedeutung, weil sie einen rechnerisch zugänglichen Weg zu stärkerem visuellem Reasoning in großen Modellen bietet, zu einer Zeit, in der die Trainingskosten für Reinforcement Fine-Tuning im Frontier-Maßstab für die meisten Forschungsgruppen unerreichbar bleiben.
Zusammenfassung
Jüngste Fortschritte beim Reinforcement Learning mit verifizierbaren Belohnungen haben die Grenzen der visuellen Reasoning-Fähigkeiten in großen Vision-Language-Modellen (LVLMs) verschoben. Das Training von LVLMs mit Reinforcement Fine-Tuning (RFT) ist jedoch rechnerisch aufwendig und stellt eine erhebliche Herausforderung für die Skalierung der Modellgröße dar. In dieser Arbeit schlagen wir ProxyThinker vor, eine Technik zur Inferenzzeit, die es großen Modellen ermöglicht, die visuellen Reasoning-Fähigkeiten von kleinen, langsam denkenden visuellen Reasonern ohne jegliches Training zu erben. Indem es die Ausgabeverteilungen von Basismodellen von denen der RFT-Reasoner subtrahiert, modifiziert ProxyThinker die Decodierungsdynamik und ruft erfolgreich das langsame Denken hervor, das sich in den entstandenen anspruchsvollen Verhaltensweisen wie Selbstverifikation und Selbstkorrektur zeigt. ProxyThinker steigert konsistent die Leistung auf anspruchsvollen visuellen Benchmarks für räumliches, mathematisches und multidisziplinäres Reasoning und ermöglicht es ungetunten Basismodellen, mit der Leistung ihrer vollständig RFT-trainierten Pendants zu konkurrieren. Darüber hinaus koordiniert unsere Implementierung mehrere Sprachmodelle effizient mit Parallelisierungstechniken und erreicht eine bis zu 38-fach schnellere Inferenz im Vergleich zu früheren Methoden zur Decodierungszeit, was den Weg für den praktischen Einsatz von ProxyThinker ebnet. Der Code ist verfügbar unter https://github.com/MrZilinXiao/ProxyThinker.
Zitation
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist ProxyThinker und welches Problem adressiert es? ProxyThinker ist eine trainingsfreie Methode zur Inferenzzeit, die langsam denkendes visuelles Reasoning-Verhalten von kleinen, mit Reinforcement Learning feinjustierten visuellen Reasonern auf größere Basis-Vision-Language-Modelle überträgt.
- Wie steuert ProxyThinker ein großes Modell? Bei jedem Decodierungsschritt addiert es die Logit-Differenz zwischen einem kleinen RFT-Reasoning-Experten und seinem kleinen Basis-Amateur-Pendant zu den Logits des großen Basismodells und ermutigt das große Modell so, Tokens zu generieren, die mit Selbstprüfung und mehrstufigem Reasoning assoziiert sind.
- Warum ist die Methode im Vergleich zu vollständigem Reinforcement Fine-Tuning nützlich? Sie vermeidet das Aktualisieren der Parameter des großen Modells, was sie zu einer praktischen Alternative macht, wenn das vollständige Reinforcement Fine-Tuning von Vision-Language-Modellen mit 32B oder 72B Parametern zu aufwendig ist.
- Wie stark verbessert ProxyThinker die visuellen Reasoning-Benchmarks? Auf fünf mathematischen und multidisziplinären Benchmarks verbessert ProxyThinker Qwen2.5-VL-32B um bis zu 2,4 Prozent durchschnittliche relative Verbesserung und Qwen2.5-VL-72B um bis zu 2,7 Prozent durchschnittliche relative Verbesserung, abhängig vom kleinen Reasoning-Experten.
- Verändert ProxyThinker den Reasoning-Stil des großen Modells? Ja, die Arbeit berichtet von mehr Zurückverfolgen, Verifikation und explizitem Denkverhalten und zeigt, dass die Methode langsam denkende Muster hervorrufen kann, statt lediglich die Wahrscheinlichkeiten der endgültigen Antwort zu verändern.
Wichtigste Beiträge
- Die Arbeit führt eine einfache Formulierung zur Decodierungszeit für den Transfer visuellen Reasonings ein, die das Logit-Delta auf Token-Ebene zwischen einem kleinen RFT-Experten und einem kleinen Amateur-Modell als Anleitung für ein größeres Basismodell verwendet.
- ProxyThinker zeigt, dass kleine visuelle Reasoner deutlich größere Modelle ohne Training verbessern können, einschließlich Vision-Language-Modelle mit 32B und 72B Parametern, evaluiert auf MathVista, MathVerse, MathVision, MMMU-Pro und R1-OneVisionBench.
- Die Methode ermöglicht es einem Qwen2.5-VL-32B-Basismodell, das von einem 7B-Experten geleitet wird, ein vollständiges 32B-RFT-Modell in einigen Benchmark-Einstellungen zu erreichen oder leicht zu übertreffen, einschließlich des in der Arbeit hervorgehobenen MathVision-Ergebnisses.
- Die Verhaltensanalyse demonstriert, dass ProxyThinker die Fähigkeit des großen Modells zur Planung von Teilzielen mit den Tendenzen des kleinen Experten zur Selbstverifikation und zum Zurückverfolgen kombinieren kann.
- Die vLLM-basierte Implementierung koordiniert mehrere Modelle effizient und berichtet eine 38-fache Beschleunigung gegenüber früheren Steuerungsimplementierungen zur Decodierungszeit im HuggingFace-Stil, was den Ansatz deutlich praktikabler macht.
Grenzen und Vorbehalte
- ProxyThinker hängt vom Zugang zu einem nützlichen kleinen RFT-visuellen Reasoner und seinem passenden Basis-Amateur-Modell ab, sodass künftige Arbeiten das Rezept auf mehr Modellfamilien und offene Experten-Amateur-Paare ausweiten könnten.
- Die Methode führt mehrere Modelle zur Inferenzzeit aus, was die Systemkomplexität im Vergleich zu einer Einzelmodell-Baseline erhöht; die optimierte vLLM-Implementierung der Arbeit reduziert diesen Overhead erheblich und zeigt, dass der Ansatz praktikabel sein kann.
- Die Leistungsgewinne variieren über Benchmarks und Experten hinweg, wobei einige Einstellungen kleinere Verbesserungen zeigen als andere; diese Variation identifiziert nützlicherweise die Expertenauswahl und die Stärke der Anleitung als wichtige Stellschrauben für künftige Reasoning-Systeme zur Decodierungszeit.
- Die Experimente konzentrieren sich auf etablierte visuelle Mathematik- und multidisziplinäre Benchmarks, sodass interaktive, langfristige und reale Bereitstellungsszenarien natürliche nächste Tests für dieselbe Anleitungsidee bleiben.
- ProxyThinker steuert das Reasoning-Verhalten zur Decodierungszeit, statt die zugrunde liegenden Gewichte des Modells zu verändern, was ein Vorteil für Zugänglichkeit und Kosten ist, während künftige Arbeiten untersuchen könnten, wie es trainingszeitliche Methoden ergänzt.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit ist am besten als ein starker und praktischer Beitrag zum effizienten visuellen Reasoning zu lesen: ProxyThinker zeigt, dass kleine trainierte Reasoner besseres langsam denkendes Verhalten in deutlich größeren Modellen zur Testzeit freisetzen können, und bietet damit eine überzeugende Alternative oder Ergänzung zu aufwendigem Reinforcement Fine-Tuning im großen Maßstab.