ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Sintesi del comunicato stampa
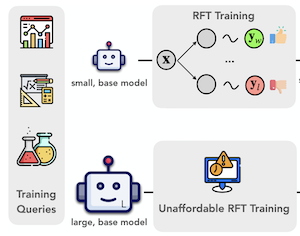
I ricercatori della Rice University, della University of Illinois Urbana-Champaign e della University of Virginia hanno sviluppato un metodo chiamato ProxyThinker che consente ai grandi vision-language model di ragionare in modo più accurato in fase di test — senza alcun addestramento aggiuntivo. Il problema che si sono proposti di risolvere è pratico: insegnare ai grandi modelli di IA a "rallentare" e a procedere passo dopo passo attraverso problemi visivi complessi richiede tipicamente un costoso reinforcement fine-tuning, un processo che esige enormi risorse di calcolo ed è stato raramente applicato a modelli con più di sette miliardi di parametri. ProxyThinker elude del tutto quel costo eseguendo durante l'inferenza due piccoli modelli di supporto accanto al grande modello — uno già ottimizzato a ragionare con attenzione e uno no — e utilizzando la differenza tra le loro distribuzioni di output per orientare la generazione token per token del grande modello verso un ragionamento più ponderato e auto-verificante. In pratica, ciò significa che il grande modello inizia a manifestare comportamenti come il backtracking, l'auto-verifica e la correzione a più passi che altrimenti produrrebbe raramente. Testando l'approccio su benchmark standard di matematica visiva e multidisciplinari, il team ha scoperto che un modello base da 32 miliardi di parametri guidato da un debole esperto di ragionamento da 7 miliardi di parametri poteva eguagliare o superare di poco le prestazioni di un dedicato modello da 32 miliardi di parametri interamente ottimizzato con Reinforcement Learning. Il team ha inoltre realizzato un'implementazione parallelizzata basata sul framework di inferenza vLLM che gira circa 38 volte più velocemente rispetto ai precedenti metodi di steering in fase di decoding, portando il tempo di inferenza misurato sull'orologio vicino a quello del semplice esecuzione di un singolo grande modello. Il lavoro è importante perché offre una via computazionalmente accessibile a un ragionamento visivo più forte nei grandi modelli in un momento in cui i costi di addestramento del reinforcement fine-tuning alla scala di frontiera restano fuori portata per la maggior parte dei gruppi di ricerca.
abstract
I recenti progressi nel Reinforcement Learning con ricompense verificabili hanno spinto i confini delle capacità di ragionamento visivo nei large vision-language model (LVLM). Tuttavia, addestrare gli LVLM con reinforcement fine-tuning (RFT) è computazionalmente costoso, ponendo una sfida significativa alla scalabilità della dimensione del modello. In questo lavoro, proponiamo ProxyThinker, una tecnica in fase di inferenza che consente ai grandi modelli di ereditare le capacità di ragionamento visivo da piccoli ragionatori visivi slow-thinking senza alcun addestramento. Sottraendo le distribuzioni di output dei modelli base da quelle dei ragionatori RFT, ProxyThinker modifica le dinamiche di decoding ed elicita con successo il ragionamento slow-thinking dimostrato dai sofisticati comportamenti emersi come l'auto-verifica e l'auto-correzione. ProxyThinker incrementa in modo costante le prestazioni su benchmark visivi impegnativi di ragionamento spaziale, matematico e multidisciplinare, consentendo a modelli base non ottimizzati di competere con le prestazioni delle loro controparti RFT a piena scala. Inoltre, la nostra implementazione coordina in modo efficiente più modelli linguistici con tecniche di parallelismo e raggiunge un'inferenza fino a 38 $\times$ più veloce rispetto ai precedenti metodi in fase di decoding, aprendo la strada all'impiego pratico di ProxyThinker. Il codice è disponibile su https://github.com/MrZilinXiao/ProxyThinker.
citazione
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è ProxyThinker e quale problema affronta? ProxyThinker è un metodo in fase di inferenza e privo di addestramento che trasferisce il comportamento di ragionamento visivo slow-thinking da piccoli ragionatori visivi ottimizzati con Reinforcement Learning a più grandi vision-language model base.
- Come orienta ProxyThinker un grande modello? A ciascun passo di decoding, aggiunge ai logit del grande modello base la differenza di logit tra un piccolo esperto di ragionamento RFT e la sua controparte amatoriale base di piccole dimensioni, incoraggiando il grande modello a generare token associati all'auto-verifica e al ragionamento a più passi.
- Perché il metodo è utile rispetto al reinforcement fine-tuning completo? Evita di aggiornare i parametri del grande modello, il che lo rende un'alternativa pratica quando il reinforcement fine-tuning a piena scala di vision-language model da 32B o 72B è troppo costoso.
- Di quanto ProxyThinker migliora i benchmark di ragionamento visivo? Su cinque benchmark matematici e multidisciplinari, ProxyThinker migliora Qwen2.5-VL-32B con un miglioramento relativo medio fino al 2,4 percento e Qwen2.5-VL-72B con un miglioramento relativo medio fino al 2,7 percento a seconda del piccolo esperto di ragionamento.
- ProxyThinker cambia lo stile di ragionamento del grande modello? Sì, l'articolo riporta più comportamenti di backtracking, verifica e pensiero esplicito, mostrando che il metodo può elicitare schemi di slow-thinking anziché limitarsi a modificare le probabilità della risposta finale.
Principali contributi
- L'articolo introduce una semplice formulazione in fase di decoding per il trasferimento del ragionamento visivo che utilizza il delta di logit a livello di token tra un piccolo esperto RFT e un piccolo modello amatoriale come guida per un grande modello base.
- ProxyThinker mostra che piccoli ragionatori visivi possono migliorare modelli sostanzialmente più grandi senza addestramento, inclusi vision-language model da 32B e 72B valutati su MathVista, MathVerse, MathVision, MMMU-Pro e R1-OneVisionBench.
- Il metodo consente a un modello base Qwen2.5-VL-32B guidato da un esperto da 7B di eguagliare o superare di poco un modello RFT completo da 32B in alcune configurazioni di benchmark, incluso il risultato su MathVision evidenziato nell'articolo.
- L'analisi comportamentale dimostra che ProxyThinker può combinare la capacità di pianificazione di sottobiettivi del grande modello con le tendenze all'auto-verifica e al backtracking del piccolo esperto.
- L'implementazione basata su vLLM coordina più modelli in modo efficiente e riporta uno speedup di 38x rispetto alle precedenti implementazioni di steering in fase di decoding in stile HuggingFace, rendendo l'approccio molto più pratico.
Limiti e avvertenze
- ProxyThinker dipende dalla disponibilità di un utile piccolo ragionatore visivo RFT e del relativo modello amatoriale base corrispondente, perciò lavori futuri potrebbero ampliare la ricetta a più famiglie di modelli e a coppie esperto-amatore aperte.
- Il metodo esegue più modelli in fase di inferenza, il che aggiunge complessità di sistema rispetto a una baseline a modello singolo; l'implementazione vLLM ottimizzata dell'articolo riduce sostanzialmente questo sovraccarico e mostra che l'approccio può essere pratico.
- I guadagni di prestazioni variano tra benchmark ed esperti, con alcune configurazioni che mostrano miglioramenti minori di altre; questa variazione individua in modo utile la selezione dell'esperto e l'intensità della guidance come manopole importanti per i futuri sistemi di ragionamento in fase di decoding.
- Gli esperimenti si concentrano su affermati benchmark di matematica visiva e multidisciplinari, lasciando gli scenari interattivi, a lungo orizzonte e di impiego nel mondo reale come naturali prossimi test per la stessa idea di guidance.
- ProxyThinker orienta il comportamento di ragionamento in fase di decoding anziché modificare i pesi sottostanti del modello, il che è un pregio in termini di accessibilità e costo, mentre lavori futuri potrebbero studiare come si combini con i metodi in fase di addestramento.
Come interpretare questo risultato
Questo articolo è meglio interpretato come un contributo solido e pratico al ragionamento visivo efficiente: ProxyThinker mostra che piccoli ragionatori addestrati possono sbloccare un migliore comportamento slow-thinking in modelli molto più grandi in fase di test, offrendo un'alternativa o un complemento convincente al costoso reinforcement fine-tuning a piena scala.