ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Resumen de prensa
Investigadores de la Universidad Rice, la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han desarrollado un método llamado ProxyThinker que permite que los grandes modelos de visión y lenguaje razonen con más cuidado en tiempo de prueba, sin ningún entrenamiento adicional. El problema que se propusieron resolver es de orden práctico: enseñar a los grandes modelos de IA a "ir más despacio" y resolver problemas visuales complejos paso a paso suele requerir un costoso ajuste fino por refuerzo, un proceso que exige enormes recursos de cómputo y que rara vez se ha aplicado a modelos de más de siete mil millones de parámetros. ProxyThinker evita por completo ese costo ejecutando dos pequeños modelos acompañantes junto al modelo grande durante la inferencia —uno que ya ha sido ajustado para razonar con cuidado y otro que no— y usando la diferencia entre sus distribuciones de salida para orientar la generación token a token del modelo grande hacia un razonamiento más deliberado y autoverificable. En la práctica, esto significa que el modelo grande empieza a exhibir comportamientos como el retroceso, la autoverificación y la corrección en múltiples pasos que de otro modo rara vez produciría. Al probar el enfoque en benchmarks estándar de matemáticas visuales y multidisciplinares, el equipo descubrió que un modelo base de 32 mil millones de parámetros, guiado por un experto en razonamiento débil de 7 mil millones de parámetros, podía igualar o superar ligeramente el rendimiento de un modelo dedicado de 32 mil millones de parámetros que había sido completamente ajustado con aprendizaje por refuerzo. El equipo también diseñó una implementación paralelizada sobre el marco de inferencia vLLM que se ejecuta unas 38 veces más rápido que los métodos previos de orientación en tiempo de decodificación, acercando el tiempo de inferencia real al de simplemente ejecutar un único modelo grande. El trabajo es relevante porque ofrece una vía computacionalmente accesible hacia un razonamiento visual más sólido en los modelos grandes, en un momento en que los costos de entrenamiento del ajuste fino por refuerzo a escala de frontera siguen estando fuera del alcance de la mayoría de los grupos de investigación.
resumen
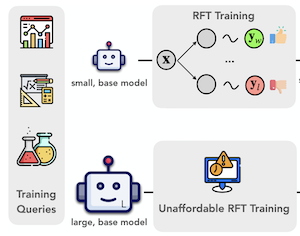
Los avances recientes en aprendizaje por refuerzo con recompensas verificables han ampliado los límites de las capacidades de razonamiento visual en los grandes modelos de visión y lenguaje (LVLMs). Sin embargo, entrenar LVLMs mediante ajuste fino por refuerzo (RFT) es computacionalmente costoso, lo que plantea un desafío significativo para escalar el tamaño de los modelos. En este trabajo, proponemos ProxyThinker, una técnica aplicada en tiempo de inferencia que permite que los modelos grandes hereden las capacidades de razonamiento visual de razonadores visuales pequeños y de pensamiento lento sin ningún tipo de entrenamiento. Al restar las distribuciones de salida de los modelos base de las de los razonadores RFT, ProxyThinker modifica la dinámica de decodificación y logra suscitar el razonamiento de pensamiento lento que se manifiesta en comportamientos sofisticados emergentes, como la autoverificación y la autocorrección. ProxyThinker mejora de forma consistente el rendimiento en benchmarks visuales exigentes de razonamiento espacial, matemático y multidisciplinar, lo que permite que modelos base sin ajustar compitan con el rendimiento de sus contrapartes RFT a escala completa. Además, nuestra implementación coordina de manera eficiente múltiples modelos de lenguaje mediante técnicas de paralelismo y logra una inferencia hasta 38 $\times$ más rápida en comparación con métodos previos aplicados en tiempo de decodificación, allanando el camino para el despliegue práctico de ProxyThinker. El código está disponible en https://github.com/MrZilinXiao/ProxyThinker.
cita
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es ProxyThinker y qué problema aborda? ProxyThinker es un método aplicado en tiempo de inferencia y sin entrenamiento que transfiere el comportamiento de razonamiento visual de pensamiento lento desde pequeños razonadores visuales ajustados por refuerzo hacia modelos base de visión y lenguaje más grandes.
- ¿Cómo orienta ProxyThinker a un modelo grande? En cada paso de decodificación, añade a los logits del modelo base grande la diferencia de logits entre un pequeño experto de razonamiento RFT y su contraparte base pequeña amateur, animando al modelo grande a generar tokens asociados con la autoverificación y el razonamiento en múltiples pasos.
- ¿Por qué es útil el método en comparación con el ajuste fino por refuerzo completo? Evita actualizar los parámetros del modelo grande, lo que lo convierte en una alternativa práctica cuando el ajuste fino por refuerzo a escala completa de modelos de visión y lenguaje de 32B o 72B resulta demasiado costoso.
- ¿Cuánto mejora ProxyThinker los benchmarks de razonamiento visual? En cinco benchmarks matemáticos y multidisciplinares, ProxyThinker mejora a Qwen2.5-VL-32B hasta en un 2.4 por ciento de mejora relativa promedio y a Qwen2.5-VL-72B hasta en un 2.7 por ciento de mejora relativa promedio, según el pequeño experto de razonamiento.
- ¿Cambia ProxyThinker el estilo de razonamiento del modelo grande? Sí, el artículo reporta más comportamientos de retroceso, verificación y pensamiento explícito, lo que demuestra que el método puede suscitar patrones de pensamiento lento en lugar de simplemente cambiar las probabilidades de la respuesta final.
Contribuciones principales
- El artículo introduce una formulación sencilla aplicada en tiempo de decodificación para la transferencia de razonamiento visual que utiliza el delta de logits a nivel de token entre un pequeño experto RFT y un pequeño modelo amateur como guía para un modelo base más grande.
- ProxyThinker demuestra que pequeños razonadores visuales pueden mejorar sustancialmente modelos mucho más grandes sin entrenamiento, incluidos modelos de visión y lenguaje de 32B y 72B evaluados en MathVista, MathVerse, MathVision, MMMU-Pro y R1-OneVisionBench.
- El método permite que un modelo base Qwen2.5-VL-32B guiado por un experto de 7B iguale o supere ligeramente a un modelo RFT completo de 32B en algunas configuraciones de benchmark, incluido el resultado de MathVision destacado en el artículo.
- El análisis del comportamiento demuestra que ProxyThinker puede combinar la capacidad de planificación de submetas del modelo grande con las tendencias de autoverificación y retroceso del pequeño experto.
- La implementación basada en vLLM coordina múltiples modelos de manera eficiente y reporta una aceleración de 38x sobre implementaciones previas de orientación en tiempo de decodificación al estilo de HuggingFace, lo que hace que el enfoque sea mucho más práctico.
Limitaciones y advertencias
- ProxyThinker depende de tener acceso a un pequeño razonador visual RFT útil y a su correspondiente modelo base amateur, por lo que el trabajo futuro podría ampliar la receta a más familias de modelos y a pares experto-amateur abiertos.
- El método ejecuta múltiples modelos en tiempo de inferencia, lo que añade complejidad al sistema en comparación con una línea base de un solo modelo; la implementación optimizada en vLLM del artículo reduce sustancialmente esta sobrecarga y demuestra que el enfoque puede ser práctico.
- Las ganancias de rendimiento varían según los benchmarks y los expertos, y algunas configuraciones muestran mejoras menores que otras; esta variación identifica de manera útil la selección del experto y la intensidad de la guía como perillas importantes para futuros sistemas de razonamiento en tiempo de decodificación.
- Los experimentos se centran en benchmarks consolidados de matemáticas visuales y multidisciplinares, dejando los escenarios interactivos, de largo horizonte y de despliegue en el mundo real como pruebas naturales siguientes para la misma idea de guía.
- ProxyThinker orienta el comportamiento de razonamiento en tiempo de decodificación en lugar de cambiar los pesos subyacentes del modelo, lo cual es una ventaja para la accesibilidad y el costo, mientras que el trabajo futuro podría estudiar cómo complementa a los métodos aplicados en tiempo de entrenamiento.
Cómo interpretar este resultado
Este artículo se lee mejor como una contribución sólida y práctica al razonamiento visual eficiente: ProxyThinker demuestra que pequeños razonadores entrenados pueden desbloquear un mejor comportamiento de pensamiento lento en modelos mucho más grandes en tiempo de prueba, ofreciendo una alternativa o un complemento convincente al costoso ajuste fino por refuerzo a escala completa.