新闻稿摘要
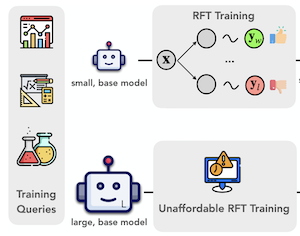
莱斯大学、伊利诺伊大学厄巴纳-香槟分校以及弗吉尼亚大学的研究人员开发了一种名为 ProxyThinker 的方法,使大型视觉语言模型能够在测试时更审慎地推理——而无需任何额外训练。他们着手解决的是一个实际问题:教大型 AI 模型“慢下来”并逐步攻克复杂的视觉问题,通常需要昂贵的强化微调,这一过程要求巨大的算力资源,并且很少被应用于超过七十亿参数的模型。ProxyThinker 完全绕开了这一成本,做法是在推理期间与大型模型并行运行两个小型陪伴模型——一个已经过微调以审慎推理,另一个则没有——并利用二者输出分布之间的差异,将大型模型逐词元的生成推向更深思熟虑、自我检查的推理。在实践中,这意味着大型模型开始表现出回溯、自我验证和多步纠正等行为,而这些行为是它平时很少产生的。在标准的视觉数学和多学科基准上测试该方法时,团队发现,一个由弱小的七十亿参数推理专家引导的三百二十亿参数基础模型,能够匹敌甚至略微超过一个经过完整强化学习微调的专用三百二十亿参数模型的性能。团队还在 vLLM 推理框架之上设计了一种并行化实现,其运行速度比早先的解码时引导方法快约 38 倍,使端到端推理时间接近于直接运行单个大型模型。这项工作的意义在于,它提供了一条在计算上可负担的途径,在前沿规模强化微调的训练成本对大多数研究团队仍遥不可及之时,为大型模型带来更强的视觉推理能力。
摘要
可验证奖励强化学习的最新进展推动了大型视觉语言模型(LVLMs)视觉推理能力的边界。然而,用强化微调(RFT)训练 LVLMs 在计算上代价高昂,对扩大模型规模构成了重大挑战。在这项工作中,我们提出 ProxyThinker,一种推理时技术,使大型模型无需任何训练即可从小型、慢思考的视觉推理器继承视觉推理能力。通过从 RFT 推理器的输出分布中减去基础模型的输出分布,ProxyThinker 改变了解码动态,并成功诱发出由自我验证和自我纠正等涌现的复杂行为所体现的慢思考推理。ProxyThinker 在空间、数学和多学科推理的高难度视觉基准上持续提升性能,使未经微调的基础模型能够与其全尺度 RFT 对应模型的性能相竞争。此外,我们的实现借助并行化技术高效地协调多个语言模型,相比以往的解码时方法实现了高达 38 $\times$ 的推理加速,为 ProxyThinker 的实际部署铺平了道路。代码可在 https://github.com/MrZilinXiao/ProxyThinker 获取。
引用
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 ProxyThinker,它解决了什么问题?ProxyThinker 是一种免训练的推理时方法,能将慢思考的视觉推理行为从小型的强化微调视觉推理器迁移到更大的基础视觉语言模型上。
- ProxyThinker 如何引导大型模型?在每个解码步骤,它将一个小型 RFT 推理专家与其小型基础“业余”对应模型之间的 logit 差值加到大型基础模型的 logits 上,鼓励大型模型生成与自我检查和多步推理相关联的词元。
- 与完整的强化微调相比,该方法为何有用?它避免了更新大型模型的参数,这使其在对 32B 或 72B 视觉语言模型进行全尺度强化微调过于昂贵时,成为一种实用的替代方案。
- ProxyThinker 对视觉推理基准的提升有多大?在五个数学和多学科基准上,ProxyThinker 视所用小型推理专家而定,使 Qwen2.5-VL-32B 的平均相对提升最高达 2.4%,使 Qwen2.5-VL-72B 的平均相对提升最高达 2.7%。
- ProxyThinker 是否改变了大型模型的推理风格?是的,论文报告称出现了更多的回溯、验证和显式思考行为,表明该方法能够诱发慢思考模式,而不仅仅是改变最终答案的概率。
主要贡献
- 论文为视觉推理迁移引入了一种简单的解码时表述,它使用一个小型 RFT 专家与一个小型业余模型之间的词元级 logit 差值,作为对更大基础模型的引导。
- ProxyThinker 表明,小型视觉推理器无需训练即可显著改善大得多的模型,包括在 MathVista、MathVerse、MathVision、MMMU-Pro 和 R1-OneVisionBench 上评估的 32B 和 72B 视觉语言模型。
- 该方法使一个由 7B 专家引导的 Qwen2.5-VL-32B 基础模型,在某些基准设置(包括论文重点指出的 MathVision 结果)上能够匹敌甚至略微超过一个完整的 32B RFT 模型。
- 行为分析表明,ProxyThinker 能够将大型模型的子目标规划能力与小型专家的自我验证和回溯倾向结合起来。
- 基于 vLLM 的实现高效地协调多个模型,并报告相比早先 HuggingFace 风格的解码时引导实现实现了 38 倍的加速,使该方法实用得多。
局限与注意事项
- ProxyThinker 依赖于能够获取一个有用的小型 RFT 视觉推理器及其匹配的基础业余模型,因此未来工作可将这一配方推广到更多模型族和开放的专家-业余配对。
- 该方法在推理时运行多个模型,相比单模型基线增加了系统复杂度;论文经过优化的 vLLM 实现大幅降低了这一开销,并表明该方法可以做到实用。
- 性能增益因基准和专家而异,某些设置的改善小于其他设置;这种差异有益地将专家选择和引导强度确定为未来解码时推理系统的重要旋钮。
- 实验聚焦于已确立的视觉数学和多学科基准,将交互式、长程以及真实世界部署场景留作同一引导思想的自然下一步测试。
- ProxyThinker 在解码时引导推理行为,而非改变模型的底层权重,这对于可及性和成本而言是一个优点,同时未来工作可研究它如何与训练时方法互补。
如何理解这一结果
这篇论文最好被理解为对高效视觉推理的一项有力且实用的贡献:ProxyThinker 表明,小型的、经过训练的推理器能够在测试时解锁大得多的模型中更好的慢思考行为,为昂贵的全尺度强化微调提供了一个引人注目的替代或补充方案。