보도 자료 요약
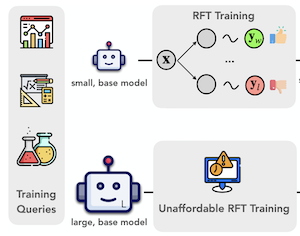
라이스 대학교, University of Illinois Urbana-Champaign, 버지니아 대학교의 연구자들은 추가 학습 없이도 대형 비전-언어 모델이 테스트 시점에 더 신중하게 추론하도록 하는 ProxyThinker라는 방법을 개발했다. 이들이 해결하고자 한 문제는 실용적인 것이다. 대형 AI 모델에게 "속도를 늦추고" 복잡한 시각 문제를 단계별로 풀어나가도록 가르치는 일은 일반적으로 비싼 강화 미세조정을 필요로 하는데, 이 과정은 막대한 연산 자원을 요구하며 70억 개를 넘는 파라미터를 가진 모델에는 거의 적용된 적이 없다. ProxyThinker는 추론 과정에서 대형 모델과 나란히 두 개의 작은 동반 모델 — 이미 신중하게 추론하도록 미세조정된 모델 하나와 그렇지 않은 모델 하나 — 을 실행하고, 그들의 출력 분포 간 차이를 사용해 대형 모델의 토큰 단위 생성을 더 신중하고 자기 점검적인 추론 쪽으로 유도함으로써 이 비용을 완전히 우회한다. 실제로 이는 대형 모델이 그렇지 않았다면 거의 만들어내지 않았을 되짚기, 자기 검증, 다단계 수정과 같은 행동을 보이기 시작함을 의미한다. 표준 시각 수학 및 다학제 벤치마크에서 이 접근법을 시험한 결과, 연구팀은 약한 70억 파라미터 추론 전문가가 유도한 320억 파라미터 기본 모델이 강화학습으로 완전히 미세조정된 전용 320억 파라미터 모델의 성능과 맞먹거나 약간 능가할 수 있음을 발견했다. 연구팀은 또한 vLLM 추론 프레임워크 위에 병렬화된 구현을 설계했는데, 이는 이전의 디코딩 시점 유도 방법보다 약 38배 빠르게 작동하여 벽시계 추론 시간을 단일 대형 모델을 그냥 실행하는 것에 근접하게 만든다. 이 연구가 중요한 이유는, 최전선 규모의 강화 미세조정 학습 비용이 대부분의 연구 그룹에게 여전히 감당하기 어려운 시점에, 대형 모델에서 더 강력한 시각 추론으로 가는 계산적으로 접근 가능한 경로를 제공하기 때문이다.
초록
검증 가능한 보상을 활용한 강화학습의 최근 발전은 대형 비전-언어 모델(LVLM)의 시각 추론 능력의 한계를 넓혀 왔다. 그러나 강화 미세조정(RFT)으로 LVLM을 학습하는 것은 계산 비용이 많이 들어, 모델 크기를 확장하는 데 상당한 어려움을 제기한다. 본 연구에서 우리는 대형 모델이 어떠한 학습도 없이 작고 느리게 사고하는 시각 추론기로부터 시각 추론 능력을 물려받을 수 있게 하는 추론 시점 기법인 ProxyThinker를 제안한다. RFT 추론기의 출력 분포에서 기본 모델의 출력 분포를 빼는 방식으로, ProxyThinker는 디코딩 역학을 수정하고 자기 검증 및 자기 수정과 같은 정교한 행동으로 나타나는 느린 사고 추론을 성공적으로 이끌어낸다. ProxyThinker는 공간, 수학, 다학제 추론에 관한 까다로운 시각 벤치마크에서 일관되게 성능을 향상시켜, 조정되지 않은 기본 모델이 완전한 규모의 RFT 대응 모델의 성능과 경쟁할 수 있게 한다. 더 나아가 우리의 구현은 병렬화 기법으로 여러 언어 모델을 효율적으로 조율하여, 이전의 디코딩 시점 방법들에 비해 최대 38$\times$ 빠른 추론을 달성하며, ProxyThinker의 실용적 배포를 위한 길을 연다. 코드는 https://github.com/MrZilinXiao/ProxyThinker 에서 이용할 수 있다.
인용
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- ProxyThinker란 무엇이며 어떤 문제를 다루는가? ProxyThinker는 작은 강화 미세조정 시각 추론기로부터 느린 사고의 시각 추론 행동을 더 큰 기본 비전-언어 모델로 전이하는, 학습이 필요 없는 추론 시점 방법이다.
- ProxyThinker는 대형 모델을 어떻게 유도하는가? 각 디코딩 단계에서, 작은 RFT 추론 전문가와 그에 대응하는 작은 기본 아마추어 모델 사이의 로짓 차이를 대형 기본 모델의 로짓에 더해, 대형 모델이 자기 점검 및 다단계 추론과 연관된 토큰을 생성하도록 장려한다.
- 이 방법은 완전한 강화 미세조정에 비해 왜 유용한가? 이 방법은 대형 모델의 파라미터를 갱신하지 않으므로, 320억 또는 720억 비전-언어 모델의 완전 규모 강화 미세조정이 너무 비쌀 때 실용적인 대안이 된다.
- ProxyThinker는 시각 추론 벤치마크를 얼마나 향상시키는가? 다섯 개의 수학 및 다학제 벤치마크에서, ProxyThinker는 작은 추론 전문가에 따라 Qwen2.5-VL-32B를 평균 상대 개선 최대 2.4퍼센트, Qwen2.5-VL-72B를 평균 상대 개선 최대 2.7퍼센트만큼 향상시킨다.
- ProxyThinker는 대형 모델의 추론 방식을 바꾸는가? 그렇다. 논문은 더 많은 되짚기, 검증, 명시적 사고 행동을 보고하며, 이 방법이 단지 최종 답의 확률을 바꾸는 것이 아니라 느린 사고 패턴을 이끌어낼 수 있음을 보여준다.
주요 기여
- 이 논문은 작은 RFT 전문가와 작은 아마추어 모델 사이의 토큰 단위 로짓 차이를 더 큰 기본 모델을 위한 가이드로 사용하는, 시각 추론 전이를 위한 간단한 디코딩 시점 정식화를 도입한다.
- ProxyThinker는 MathVista, MathVerse, MathVision, MMMU-Pro, R1-OneVisionBench에서 평가된 320억 및 720억 비전-언어 모델을 포함하여, 작은 시각 추론기가 학습 없이도 상당히 더 큰 모델을 향상시킬 수 있음을 보여준다.
- 이 방법은 70억 전문가가 유도한 Qwen2.5-VL-32B 기본 모델이 논문에서 강조된 MathVision 결과를 포함하여 일부 벤치마크 설정에서 완전한 320억 RFT 모델과 맞먹거나 약간 능가할 수 있게 한다.
- 행동 분석은 ProxyThinker가 대형 모델의 하위 목표 계획 능력과 작은 전문가의 자기 검증 및 되짚기 경향을 결합할 수 있음을 입증한다.
- vLLM 기반 구현은 여러 모델을 효율적으로 조율하며, 이전 HuggingFace 방식의 디코딩 시점 유도 구현 대비 38배의 속도 향상을 보고하여 이 접근법을 훨씬 더 실용적으로 만든다.
한계 및 유의 사항
- ProxyThinker는 유용한 작은 RFT 시각 추론기와 그에 맞는 기본 아마추어 모델에 대한 접근에 의존하므로, 향후 연구는 이 방식을 더 많은 모델 계열과 공개된 전문가-아마추어 쌍으로 확장할 수 있다.
- 이 방법은 추론 시점에 여러 모델을 실행하므로 단일 모델 기준선에 비해 시스템 복잡성을 더한다. 논문의 최적화된 vLLM 구현은 이 부담을 상당히 줄이고 접근법이 실용적일 수 있음을 보여준다.
- 성능 향상은 벤치마크와 전문가에 따라 다르며, 일부 설정은 다른 설정보다 작은 개선을 보인다. 이러한 변동은 전문가 선택과 가이드 강도를 향후 디코딩 시점 추론 시스템의 중요한 조절 요소로 유용하게 식별해 준다.
- 실험은 확립된 시각 수학 및 다학제 벤치마크에 초점을 맞추어, 상호작용적이고 장기적이며 실세계 배포 시나리오를 동일한 가이드 아이디어에 대한 자연스러운 다음 시험으로 남겨둔다.
- ProxyThinker는 모델의 기저 가중치를 바꾸는 대신 디코딩 시점에 추론 행동을 유도하는데, 이는 접근성과 비용 면에서 장점이며, 향후 연구는 이것이 학습 시점 방법을 어떻게 보완하는지 연구할 수 있다.
이 결과를 읽는 방법
이 논문은 효율적인 시각 추론에 대한 강력하고 실용적인 기여로 읽는 것이 가장 좋다. ProxyThinker는 작은 학습된 추론기가 훨씬 더 큰 모델에서 더 나은 느린 사고 행동을 테스트 시점에 이끌어낼 수 있음을 보여주며, 비싼 완전 규모 강화 미세조정에 대한 설득력 있는 대안 또는 보완책을 제시한다.