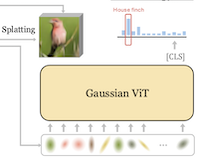
GViT: Representing Images as Gaussians for Visual Recognition
Resumen de prensa
Investigadores de la Universidad Rice y UC Irvine han construido un nuevo sistema de clasificación de imágenes que descarta el enfoque convencional de alimentar a una red neuronal con una cuadrícula de píxeles o parches rectangulares, reemplazando esa entrada con un conjunto compacto de manchas matemáticas llamadas Gaussianas 2D. El sistema, denominado GViT, funciona entrenando una pequeña red codificadora para describir cada imagen usando unos pocos cientos de Gaussianas, donde cada mancha lleva información sobre su posición, tamaño, orientación, color y opacidad. La parte ingeniosa de la configuración de entrenamiento es que el modelo de clasificación y el codificador de Gaussianas se entrenan juntos en un bucle de retroalimentación: los gradientes del clasificador —en esencia, señales sobre qué partes de una imagen importan para identificar su contenido— se retroalimentan para dirigir las Gaussianas hacia las regiones que son realmente útiles para el reconocimiento, en lugar de dejar que se distribuyan uniformemente por un fondo poco informativo. Usando este enfoque en el benchmark estándar ImageNet-1k, la mejor versión de GViT alcanzó una precisión top-1 del 76,9% con una arquitectura ViT-Base, en comparación con aproximadamente el 78,7% de un ViT convencional basado en parches de tamaño similar: una diferencia de menos de dos puntos porcentuales al tiempo que usa una representación de entrada fundamentalmente diferente y mucho más compacta. El trabajo importa no porque supere de inmediato a los sistemas existentes, sino porque demuestra que primitivas geométricas intermedias e interpretables por humanos pueden sustentar un reconocimiento visual competitivo, y como subproducto las Gaussianas aprendidas tienden a agruparse alrededor de las partes de una escena que el modelo encuentra más discriminativas, ofreciendo una forma ligera de explicabilidad que los modelos basados en cuadrículas de píxeles no proporcionan de forma natural.
resumen
Presentamos GVIT, un marco de clasificación que abandona las representaciones de entrada convencionales basadas en cuadrículas de píxeles o de parches en favor de un conjunto compacto de Gaussianas 2D aprendibles. Cada imagen se codifica como unos pocos cientos de Gaussianas cuyas posiciones, escalas, orientaciones, colores y opacidades se optimizan conjuntamente con un clasificador ViT entrenado sobre estas representaciones. Reutilizamos los gradientes del clasificador como guía constructiva, dirigiendo las Gaussianas hacia regiones relevantes para la clase, mientras un renderizador diferenciable optimiza una pérdida de reconstrucción de la imagen. Demostramos que, mediante representaciones de entrada basadas en Gaussianas 2D acopladas con nuestra guía GVIT, usando una arquitectura ViT relativamente estándar, se iguala estrechamente el rendimiento de un ViT tradicional basado en parches, alcanzando una precisión top-1 del 76,9% en Imagenet-1k usando una arquitectura ViT-B.
cita
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es GViT y qué problema aborda? GViT es un marco de reconocimiento visual que reemplaza las entradas fijas de cuadrículas de píxeles o parches con un conjunto compacto de primitivas Gaussianas 2D aprendibles, probando si las representaciones geométricas de nivel medio pueden sustentar una clasificación de imágenes competitiva.
- ¿Cómo se aprenden las Gaussianas? Un codificador de Gaussianas con eliminación de ruido predice los centros, escalas, orientaciones, colores y opacidades de las Gaussianas, mientras que un renderizador diferenciable optimiza la reconstrucción de la imagen y un clasificador ViT aporta gradientes constructivos que dirigen las Gaussianas hacia regiones relevantes para la clase.
- ¿Qué tan bien funciona GViT en ImageNet-1k? El modelo guiado GViT-B alcanza una precisión top-1 del 76,9 por ciento en ImageNet-1k, cercana al 78,7 por ciento reportado para un ViT-B/16 basado en parches de tamaño similar, al tiempo que usa una representación de entrada Gaussiana sustancialmente diferente.
- ¿Por qué es importante la guía mediante gradientes del clasificador? El artículo reporta que la guía mejora GViT-B del 73,6 por ciento al 76,9 por ciento en ImageNet-1k y mejora de forma similar los modelos más pequeños, mostrando que la colocación de Gaussianas consciente de la tarea es central para hacer que la representación sea útil para el reconocimiento.
- ¿Proporciona GViT beneficios de interpretabilidad? Sí, las covarianzas de las Gaussianas aprendidas y los mapas de atención discriminativos por clase tienden a concentrarse en regiones de la imagen relevantes para la clase, dando a la representación una explicación visual geométrica que los tokens de parches estándar no exponen de forma natural.
Contribuciones principales
- El artículo introduce una representación de imágenes compatible con ViT basada en conjuntos de primitivas Gaussianas 2D en lugar de píxeles, parches, bytes en bruto o coeficientes de frecuencia comprimidos.
- GViT propone un esquema de entrenamiento cooperativo en el que las pérdidas de reconstrucción preservan la fidelidad de la imagen mientras los gradientes del clasificador reubican activamente las Gaussianas hacia la evidencia visual discriminativa.
- Los experimentos en ImageNet-1k muestran que las entradas Gaussianas pueden alcanzar una precisión top-1 del 76,9 por ciento con una arquitectura base ViT-B, superando varias alternativas de entrada no basadas en parches listadas en el artículo y quedando a 1,8 puntos de un ViT-B/16 convencional basado en parches.
- Los estudios de ablación en Mini-ImageNet-100 muestran que la eliminación de ruido y la guía mediante gradientes del clasificador mejoran significativamente la colocación de las Gaussianas, con la versión guiada completa superando el ajuste de Gaussianas fuera de línea, las consultas aprendidas y la eliminación de ruido sin guía.
- El análisis muestra que las señales de escala y atención de las Gaussianas se alinean con regiones discriminativas por clase, respaldando la afirmación de que GViT ofrece una representación de reconocimiento compacta con un componente de interpretabilidad natural.
Limitaciones y advertencias
- Los ViT basados en parches siguen siendo la opción más pragmática para muchos despliegues a gran escala hoy en día, pero la pequeña diferencia de precisión de GViT en ImageNet-1k constituye un argumento sólido de que las primitivas Gaussianas son ya una representación alternativa viable y sorprendentemente competitiva.
- El número de Gaussianas se fija antes del entrenamiento, por lo que versiones futuras podrían beneficiarse de la generación, poda o reasignación dinámica; las mejoras monótonas observadas a medida que aumenta el presupuesto de Gaussianas proporcionan una orientación útil para ese siguiente paso de diseño.
- El renderizado diferenciable añade sobrecarga de memoria y cómputo, especialmente a altas resoluciones o con más de 512 Gaussianas en entrenamiento a escala de ImageNet; esto es un cuello de botella de ingeniería en torno a una representación por lo demás prometedora, más que una debilidad de la idea central.
- Los experimentos se centran en la clasificación de imágenes y en benchmarks de clasificación por transferencia, en lugar de tareas de predicción densa como la detección o la segmentación; las disposiciones de Gaussianas relevantes para la clase sugieren que esas tareas son lugares naturales para explorar la representación a continuación.
- El enfoque actual comprime, por diseño, parte del detalle fino a nivel de píxel, lo que ayuda a hacer la representación compacta e interpretable mientras deja espacio para que trabajos futuros ajusten el equilibrio entre la fidelidad de reconstrucción y la discriminación semántica.
Cómo interpretar este resultado
Este artículo se lee mejor como un argumento sólido y respaldado por evidencia de que el reconocimiento visual no tiene por qué estar ligado a cuadrículas de píxeles o parches: GViT mantiene el rendimiento en ImageNet cercano al de los ViT estándar al tiempo que introduce una representación Gaussiana interpretable que abre una dirección prometedora para futuras redes troncales de visión.