GViT: Representing Images as Gaussians for Visual Recognition
Résumé du communiqué de presse
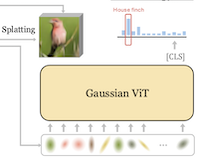
Des chercheurs de Rice University et de UC Irvine ont conçu un nouveau système de classification d'images qui abandonne l'approche conventionnelle consistant à fournir à un réseau de neurones une grille de pixels ou de parcelles rectangulaires, en remplaçant cette entrée par un ensemble compact de taches mathématiques appelées gaussiennes 2D. Le système, appelé GViT, fonctionne en entraînant un petit réseau encodeur à décrire chaque image à l'aide de quelques centaines de gaussiennes, où chaque tache porte des informations sur sa position, sa taille, son orientation, sa couleur et son opacité. L'aspect ingénieux du dispositif d'entraînement est que le modèle de classification et l'encodeur gaussien sont entraînés ensemble dans une boucle de rétroaction : les gradients du classifieur — essentiellement des signaux indiquant quelles parties d'une image comptent pour identifier son contenu — sont réinjectés pour orienter les gaussiennes vers les régions réellement utiles à la reconnaissance, plutôt que de les laisser se répartir uniformément sur un arrière-plan peu informatif. Avec cette approche sur le banc d'essai standard ImageNet-1k, la meilleure version de GViT a atteint une précision top-1 de 76,9 % avec une architecture ViT-Base, contre environ 78,7 % pour un ViT conventionnel fondé sur des parcelles de taille similaire — un écart de moins de deux points de pourcentage tout en utilisant une représentation d'entrée fondamentalement différente et bien plus compacte. Ce travail est important non pas parce qu'il surpasse immédiatement les systèmes existants, mais parce qu'il démontre que des primitives géométriques intermédiaires et interprétables par l'humain peuvent soutenir une reconnaissance visuelle compétitive ; et, comme effet secondaire, les gaussiennes apprises tendent à se regrouper autour des parties d'une scène que le modèle juge les plus discriminantes, offrant une forme légère d'explicabilité que les modèles à grille de pixels ne fournissent pas naturellement.
résumé
Nous présentons GVIT, un cadre de classification qui abandonne les représentations d'entrée conventionnelles en grille de pixels ou de parcelles au profit d'un ensemble compact de gaussiennes 2D apprenables. Chaque image est encodée sous forme de quelques centaines de gaussiennes dont les positions, les échelles, les orientations, les couleurs et les opacités sont optimisées conjointement avec un classifieur ViT entraîné sur ces représentations. Nous réutilisons les gradients du classifieur comme guidage constructif, orientant les gaussiennes vers les régions saillantes pour la classe tandis qu'un moteur de rendu différentiable optimise une perte de reconstruction d'image. Nous démontrons que, grâce aux représentations d'entrée par gaussiennes 2D couplées à notre guidage GVIT, en utilisant une architecture ViT relativement standard, on s'approche étroitement de la performance d'un ViT traditionnel fondé sur des parcelles, atteignant une précision top-1 de 76,9 % sur Imagenet-1k avec une architecture ViT-B.
citation
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce que GViT et quel problème aborde-t-il ? GViT est un cadre de reconnaissance visuelle qui remplace les entrées fixes en grille de pixels ou de parcelles par un ensemble compact de primitives gaussiennes 2D apprenables, testant si des représentations géométriques de niveau intermédiaire peuvent soutenir une classification d'images compétitive.
- Comment les gaussiennes sont-elles apprises ? Un encodeur gaussien de débruitage prédit les centres, échelles, orientations, couleurs et opacités des gaussiennes, tandis qu'un moteur de rendu différentiable optimise la reconstruction d'image et qu'un classifieur ViT fournit des gradients constructifs qui orientent les gaussiennes vers les régions saillantes pour la classe.
- Quelles sont les performances de GViT sur ImageNet-1k ? Le modèle guidé GViT-B atteint une précision top-1 de 76,9 pour cent sur ImageNet-1k, proche des 78,7 pour cent rapportés pour un ViT-B/16 fondé sur des parcelles de taille similaire, tout en utilisant une représentation d'entrée gaussienne substantiellement différente.
- Pourquoi le guidage par gradient du classifieur est-il important ? L'article rapporte que le guidage fait passer GViT-B de 73,6 pour cent à 76,9 pour cent sur ImageNet-1k et améliore de manière similaire les modèles plus petits, montrant que le placement des gaussiennes tenant compte de la tâche est central pour rendre la représentation utile à la reconnaissance.
- GViT offre-t-il des avantages en matière d'interprétabilité ? Oui, les covariances gaussiennes apprises et les cartes d'attention discriminantes pour la classe tendent à se concentrer sur les régions d'image pertinentes pour la classe, conférant à la représentation une explication visuelle géométrique que les jetons de parcelles standards n'exposent pas naturellement.
Principales contributions
- L'article introduit une représentation d'image compatible avec les ViT, fondée sur des ensembles de primitives gaussiennes 2D plutôt que sur des pixels, des parcelles, des octets bruts ou des coefficients de fréquence compressés.
- GViT propose un schéma d'entraînement coopératif dans lequel les pertes de reconstruction préservent la fidélité de l'image tandis que les gradients du classifieur déplacent activement les gaussiennes vers les preuves visuelles discriminantes.
- Les expériences sur ImageNet-1k montrent que les entrées gaussiennes peuvent atteindre une précision top-1 de 76,9 pour cent avec un squelette ViT-B, surpassant plusieurs alternatives d'entrée non fondées sur des parcelles répertoriées dans l'article et s'approchant à 1,8 point d'un ViT-B/16 conventionnel fondé sur des parcelles.
- Des ablations sur Mini-ImageNet-100 montrent que le débruitage et le guidage par gradient du classifieur améliorent significativement le placement des gaussiennes, la version entièrement guidée surpassant l'ajustement gaussien hors ligne, les requêtes apprises et le débruitage non guidé.
- L'analyse montre que l'échelle des gaussiennes et les signaux d'attention s'alignent sur les régions discriminantes pour la classe, ce qui appuie l'affirmation selon laquelle GViT offre une représentation de reconnaissance compacte dotée d'une composante d'interprétabilité naturelle.
Limites et mises en garde
- Les ViT fondés sur des parcelles restent aujourd'hui le choix le plus pragmatique pour de nombreux déploiements à grande échelle, mais le faible écart de précision de GViT sur ImageNet-1k plaide fortement en faveur du fait que les primitives gaussiennes constituent déjà une représentation alternative viable et étonnamment compétitive.
- Le nombre de gaussiennes est fixé avant l'entraînement, de sorte que de futures versions pourraient bénéficier d'une création, d'un élagage ou d'une réallocation dynamiques ; les gains monotones observés à mesure que le budget de gaussiennes augmente fournissent des indications utiles pour cette prochaine étape de conception.
- Le rendu différentiable ajoute une surcharge de mémoire et de calcul, en particulier à haute résolution ou avec plus de 512 gaussiennes lors d'un entraînement à l'échelle d'ImageNet ; il s'agit d'un goulot d'étranglement d'ingénierie autour d'une représentation par ailleurs prometteuse plutôt que d'une faiblesse de l'idée centrale.
- Les expériences se concentrent sur la classification d'images et les bancs d'essai de classification par transfert plutôt que sur des tâches de prédiction dense comme la détection ou la segmentation ; les agencements gaussiens saillants pour la classe suggèrent que ces tâches sont des terrains naturels pour explorer ensuite la représentation.
- L'approche actuelle compresse par conception une partie des détails fins au niveau du pixel, ce qui contribue à rendre la représentation compacte et interprétable tout en laissant la place à de futurs travaux pour ajuster l'équilibre entre la fidélité de reconstruction et la discrimination sémantique.
Comment interpréter ce résultat
Cet article se lit au mieux comme un argument solide et étayé par des preuves selon lequel la reconnaissance visuelle n'a pas besoin d'être liée à des grilles de pixels ou de parcelles : GViT maintient les performances sur ImageNet proches de celles des ViT standards tout en introduisant une représentation gaussienne interprétable qui ouvre une direction prometteuse pour les futurs squelettes de vision.