GViT: Representing Images as Gaussians for Visual Recognition
Resumo do comunicado de imprensa
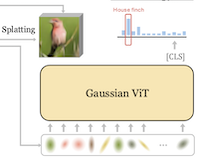
Pesquisadores da Rice University e da UC Irvine construíram um novo sistema de classificação de imagens que abandona a abordagem convencional de alimentar uma rede neural com uma grade de pixels ou patches retangulares, substituindo essa entrada por um conjunto compacto de manchas matemáticas chamadas gaussianas 2D. O sistema, chamado GViT, funciona treinando uma pequena rede codificadora para descrever cada imagem usando algumas centenas de gaussianas, em que cada mancha carrega informações sobre sua posição, tamanho, orientação, cor e opacidade. A parte engenhosa da configuração de treinamento é que o modelo de classificação e o codificador de gaussianas são treinados juntos em um laço de feedback: os gradientes do classificador — essencialmente sinais sobre quais partes de uma imagem importam para identificar seu conteúdo — são realimentados para direcionar as gaussianas às regiões que são de fato úteis para o reconhecimento, em vez de deixá-las se espalharem uniformemente por um fundo não informativo. Usando essa abordagem no benchmark padrão ImageNet-1k, a melhor versão do GViT atingiu 76,9% de acurácia top-1 com uma arquitetura ViT-Base, em comparação com cerca de 78,7% para um ViT convencional baseado em patches de tamanho semelhante — uma diferença de menos de dois pontos percentuais usando uma representação de entrada fundamentalmente diferente e muito mais compacta. O trabalho é relevante não porque supere imediatamente os sistemas existentes, mas porque demonstra que primitivas geométricas intermediárias e interpretáveis por humanos podem dar suporte a um reconhecimento visual competitivo e, como subproduto, as gaussianas aprendidas tendem a se agrupar em torno das partes de uma cena que o modelo considera mais discriminativas, oferecendo uma forma leve de explicabilidade que os modelos de grade de pixels não fornecem naturalmente.
resumo
Apresentamos o GVIT, um arcabouço de classificação que abandona as representações convencionais de entrada baseadas em grade de pixels ou de patches em favor de um conjunto compacto de gaussianas 2D aprendíveis. Cada imagem é codificada como algumas centenas de gaussianas cujas posições, escalas, orientações, cores e opacidades são otimizadas conjuntamente com um classificador ViT treinado sobre essas representações. Reutilizamos os gradientes do classificador como orientação construtiva, direcionando as gaussianas para regiões salientes de classe enquanto um renderizador diferenciável otimiza uma função de perda de reconstrução de imagem. Demonstramos que, com representações de entrada de gaussianas 2D acopladas à nossa orientação GVIT, usando uma arquitetura ViT relativamente padrão, o desempenho se aproxima muito do de um ViT tradicional baseado em patches, atingindo 76,9% de acurácia top-1 no Imagenet-1k usando uma arquitetura ViT-B.
citação
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o GViT e qual problema ele aborda? O GViT é um arcabouço de reconhecimento visual que substitui entradas fixas de pixels ou de grade de patches por um conjunto compacto de primitivas gaussianas 2D aprendíveis, testando se representações geométricas de nível intermediário podem dar suporte a uma classificação de imagens competitiva.
- Como as gaussianas são aprendidas? Um codificador gaussiano de remoção de ruído prevê os centros, escalas, orientações, cores e opacidades das gaussianas, enquanto um renderizador diferenciável otimiza a reconstrução da imagem e um classificador ViT fornece gradientes construtivos que direcionam as gaussianas para regiões salientes de classe.
- Quão bem o GViT se sai no ImageNet-1k? O modelo GViT-B guiado atinge 76,9 por cento de acurácia top-1 no ImageNet-1k, próximo dos 78,7 por cento relatados para um ViT-B/16 baseado em patches de tamanho semelhante, usando uma representação de entrada gaussiana substancialmente diferente.
- Por que a orientação por gradiente do classificador é importante? O artigo relata que a orientação melhora o GViT-B de 73,6 por cento para 76,9 por cento no ImageNet-1k e melhora de forma semelhante os modelos menores, mostrando que o posicionamento das gaussianas consciente da tarefa é central para tornar a representação útil para o reconhecimento.
- O GViT oferece benefícios de interpretabilidade? Sim, as covariâncias gaussianas aprendidas e os mapas de atenção discriminativos de classe tendem a se concentrar em regiões da imagem relevantes para a classe, conferindo à representação uma explicação visual geométrica que os tokens de patch padrão não expõem naturalmente.
Principais contribuições
- O artigo introduz uma representação de imagem compatível com ViT baseada em conjuntos de primitivas gaussianas 2D, em vez de pixels, patches, bytes brutos ou coeficientes de frequência comprimidos.
- O GViT propõe um esquema de treinamento cooperativo no qual as funções de perda de reconstrução preservam a fidelidade da imagem enquanto os gradientes do classificador realocam ativamente as gaussianas em direção a evidências visuais discriminativas.
- Os experimentos no ImageNet-1k mostram que entradas gaussianas podem atingir 76,9 por cento de acurácia top-1 com um backbone ViT-B, superando várias alternativas de entrada não baseadas em patches listadas no artigo e ficando dentro de 1,8 ponto de um ViT-B/16 convencional baseado em patches.
- Ablações no Mini-ImageNet-100 mostram que a remoção de ruído e a orientação por gradiente do classificador melhoram significativamente o posicionamento das gaussianas, com a versão totalmente guiada superando o ajuste off-line de gaussianas, as consultas aprendidas e a remoção de ruído sem orientação.
- A análise mostra que os sinais de escala gaussiana e de atenção se alinham com regiões discriminativas de classe, dando suporte à afirmação de que o GViT oferece uma representação de reconhecimento compacta com um componente natural de interpretabilidade.
Limitações e ressalvas
- Os ViTs baseados em patches continuam sendo a escolha mais pragmática para muitas implantações em larga escala atualmente, mas a pequena diferença de acurácia do GViT no ImageNet-1k constrói um forte argumento de que as primitivas gaussianas já são uma representação alternativa viável e surpreendentemente competitiva.
- O número de gaussianas é fixado antes do treinamento, de modo que versões futuras poderiam se beneficiar de geração, poda ou realocação dinâmicas; os ganhos monotônicos observados à medida que o orçamento de gaussianas aumenta fornecem orientação útil para esse próximo passo de projeto.
- A renderização diferenciável adiciona sobrecarga de memória e de computação, especialmente em altas resoluções ou com mais de 512 gaussianas em treinamento em escala do ImageNet; isso é um gargalo de engenharia em torno de uma representação que, fora isso, é promissora, em vez de uma fraqueza da ideia central.
- Os experimentos concentram-se em benchmarks de classificação de imagens e de classificação por transferência, em vez de tarefas de predição densa, como detecção ou segmentação; os arranjos de gaussianas salientes de classe sugerem que essas tarefas são lugares naturais para explorar a representação em seguida.
- A abordagem atual comprime por projeto alguns detalhes finos de pixel, o que ajuda a tornar a representação compacta e interpretável, ao mesmo tempo em que deixa espaço para que trabalhos futuros ajustem o equilíbrio entre a fidelidade de reconstrução e a discriminação semântica.
Como interpretar este resultado
Este artigo é mais bem compreendido como um forte argumento, respaldado por evidências, de que o reconhecimento visual não precisa estar atrelado a grades de pixels ou de patches: o GViT mantém o desempenho no ImageNet próximo ao dos ViTs padrão, ao mesmo tempo em que introduz uma representação gaussiana interpretável que abre uma direção promissora para futuros backbones de visão.