GViT: Representing Images as Gaussians for Visual Recognition
Tóm tắt thông cáo báo chí
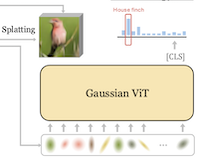
Các nhà nghiên cứu tại Rice University và UC Irvine đã xây dựng một hệ thống phân loại ảnh mới từ bỏ cách tiếp cận thông thường là đưa cho mạng nơ-ron một lưới pixel hoặc các mảng (patch) hình chữ nhật, thay thế đầu vào đó bằng một tập nhỏ gọn các khối toán học gọi là Gaussian 2D. Hệ thống mang tên GViT hoạt động bằng cách huấn luyện một mạng mã hóa nhỏ để mô tả mỗi ảnh bằng vài trăm Gaussian, trong đó mỗi khối mang thông tin về vị trí, kích thước, hướng, màu sắc và độ mờ đục của nó. Phần khéo léo trong thiết lập huấn luyện là mô hình phân loại và bộ mã hóa Gaussian được huấn luyện cùng nhau trong một vòng phản hồi: các gradient từ bộ phân loại — về cơ bản là các tín hiệu về việc phần nào của ảnh quan trọng để nhận diện nội dung của nó — được đưa trở lại để lèo lái các Gaussian hướng tới những vùng thực sự hữu ích cho việc nhận diện, thay vì để chúng trải đều trên nền không mang nhiều thông tin. Sử dụng cách tiếp cận này trên benchmark tiêu chuẩn ImageNet-1k, phiên bản tốt nhất của GViT đạt độ chính xác top-1 76.9% với kiến trúc ViT-Base, so với khoảng 78.7% cho một ViT dựa trên patch thông thường có kích thước tương tự — một khoảng cách nhỏ hơn hai điểm phần trăm trong khi sử dụng một biểu diễn đầu vào về cơ bản khác biệt và nhỏ gọn hơn nhiều. Công trình này quan trọng không phải vì nó lập tức vượt trội các hệ thống hiện có, mà vì nó chứng minh rằng các nguyên thủy hình học trung gian, có thể diễn giải được bởi con người, có thể hỗ trợ nhận diện thị giác cạnh tranh, và như một hệ quả phụ, các Gaussian được học có xu hướng tụ lại quanh những phần của cảnh mà mô hình cho là phân biệt nhất, mang lại một dạng khả năng diễn giải nhẹ mà các mô hình lưới pixel không tự nhiên cung cấp.
tóm tắt
Chúng tôi giới thiệu GVIT, một khung phân loại từ bỏ các biểu diễn đầu vào dạng lưới pixel hay patch thông thường để chuyển sang một tập nhỏ gọn các Gaussian 2D có thể học được. Mỗi ảnh được mã hóa thành vài trăm Gaussian mà vị trí, tỉ lệ, hướng, màu sắc và độ mờ đục của chúng được tối ưu hóa đồng thời với một bộ phân loại ViT được huấn luyện trên các biểu diễn này. Chúng tôi tái sử dụng các gradient của bộ phân loại làm dẫn dắt kiến tạo, lèo lái các Gaussian hướng tới những vùng nổi bật theo lớp trong khi một bộ kết xuất khả vi tối ưu hóa hàm mất mát tái tạo ảnh. Chúng tôi chứng minh rằng bằng các biểu diễn đầu vào Gaussian 2D kết hợp với dẫn dắt GVIT của chúng tôi, sử dụng một kiến trúc ViT tương đối tiêu chuẩn, gần như sánh ngang hiệu năng của một ViT dựa trên patch truyền thống, đạt độ chính xác top-1 76.9% trên Imagenet-1k bằng kiến trúc ViT-B.
trích dẫn
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- GViT là gì và nó giải quyết vấn đề nào? GViT là một khung nhận diện thị giác thay thế đầu vào dạng lưới pixel hoặc patch cố định bằng một tập nhỏ gọn các nguyên thủy Gaussian 2D có thể học được, kiểm chứng xem các biểu diễn hình học cấp trung có thể hỗ trợ phân loại ảnh cạnh tranh hay không.
- Các Gaussian được học như thế nào? Một bộ mã hóa Gaussian khử nhiễu dự đoán tâm, tỉ lệ, hướng, màu sắc và độ mờ đục của Gaussian, trong khi một bộ kết xuất khả vi tối ưu hóa việc tái tạo ảnh và một bộ phân loại ViT cung cấp các gradient kiến tạo lèo lái các Gaussian hướng tới những vùng nổi bật theo lớp.
- GViT hoạt động tốt đến mức nào trên ImageNet-1k? Mô hình GViT-B có dẫn dắt đạt độ chính xác top-1 76.9 phần trăm trên ImageNet-1k, gần với mức 78.7 phần trăm được báo cáo cho một ViT-B/16 dựa trên patch có kích thước tương tự, trong khi sử dụng một biểu diễn đầu vào Gaussian khác biệt đáng kể.
- Tại sao dẫn dắt bằng gradient của bộ phân loại lại quan trọng? Bài báo cho biết dẫn dắt cải thiện GViT-B từ 73.6 phần trăm lên 76.9 phần trăm trên ImageNet-1k và cải thiện tương tự các mô hình nhỏ hơn, cho thấy việc đặt Gaussian nhận biết tác vụ là trọng tâm để làm cho biểu diễn này hữu ích cho nhận diện.
- GViT có mang lại lợi ích về khả năng diễn giải không? Có, các ma trận hiệp phương sai Gaussian được học và các bản đồ chú ý phân biệt theo lớp có xu hướng tập trung vào những vùng ảnh liên quan đến lớp, mang lại cho biểu diễn một lời giải thích thị giác mang tính hình học mà các token patch tiêu chuẩn không tự nhiên bộc lộ.
Đóng góp chính
- Bài báo giới thiệu một biểu diễn ảnh tương thích với ViT dựa trên các tập nguyên thủy Gaussian 2D thay vì pixel, patch, byte thô, hay hệ số tần số nén.
- GViT đề xuất một sơ đồ huấn luyện hợp tác trong đó các hàm mất mát tái tạo bảo toàn độ trung thực của ảnh còn các gradient của bộ phân loại chủ động di dời các Gaussian hướng tới bằng chứng thị giác có tính phân biệt.
- Các thí nghiệm trên ImageNet-1k cho thấy đầu vào Gaussian có thể đạt độ chính xác top-1 76.9 phần trăm với backbone ViT-B, vượt trội nhiều lựa chọn đầu vào không-phải-patch được liệt kê trong bài và đạt trong vòng 1.8 điểm so với một ViT-B/16 dựa trên patch thông thường.
- Các phân tích loại bỏ trên Mini-ImageNet-100 cho thấy việc khử nhiễu và dẫn dắt bằng gradient của bộ phân loại cải thiện đáng kể việc đặt Gaussian, với phiên bản có dẫn dắt đầy đủ vượt trội việc khớp Gaussian ngoại tuyến, các truy vấn được học, và việc khử nhiễu không có dẫn dắt.
- Phân tích cho thấy tỉ lệ Gaussian và các tín hiệu chú ý khớp với các vùng có tính phân biệt theo lớp, ủng hộ tuyên bố rằng GViT mang lại một biểu diễn nhận diện nhỏ gọn với một thành phần khả năng diễn giải tự nhiên.
Hạn chế và lưu ý
- Các ViT dựa trên patch vẫn là lựa chọn thực dụng nhất cho nhiều triển khai quy mô lớn hiện nay, nhưng khoảng cách độ chính xác nhỏ của GViT trên ImageNet-1k tạo nên một lập luận mạnh mẽ rằng các nguyên thủy Gaussian đã là một biểu diễn thay thế khả thi và cạnh tranh đáng ngạc nhiên.
- Số lượng Gaussian được cố định trước khi huấn luyện, nên các phiên bản tương lai có thể hưởng lợi từ việc sinh thêm, cắt tỉa, hay tái phân bổ động; những cải thiện đơn điệu quan sát được khi ngân sách Gaussian tăng lên cung cấp dẫn dắt hữu ích cho bước thiết kế tiếp theo đó.
- Việc kết xuất khả vi làm tăng chi phí bộ nhớ và tính toán, đặc biệt ở độ phân giải cao hoặc với hơn 512 Gaussian trong huấn luyện quy mô ImageNet; đây là một nút thắt kỹ thuật quanh một biểu diễn vốn đầy hứa hẹn chứ không phải một điểm yếu của ý tưởng cốt lõi.
- Các thí nghiệm tập trung vào phân loại ảnh và các benchmark phân loại chuyển giao thay vì các tác vụ dự đoán dày đặc như phát hiện hay phân vùng; các bố cục Gaussian nổi bật theo lớp gợi ý rằng những tác vụ đó là nơi tự nhiên để khám phá biểu diễn này tiếp theo.
- Cách tiếp cận hiện tại nén bỏ một phần chi tiết pixel tinh vi theo thiết kế, điều giúp làm cho biểu diễn nhỏ gọn và dễ diễn giải đồng thời để lại không gian cho công trình tương lai điều chỉnh cân bằng giữa độ trung thực tái tạo và tính phân biệt ngữ nghĩa.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một lập luận mạnh mẽ được hậu thuẫn bằng bằng chứng rằng nhận diện thị giác không nhất thiết phải bị ràng buộc với lưới pixel hay patch: GViT giữ hiệu năng ImageNet gần với các ViT tiêu chuẩn trong khi giới thiệu một biểu diễn Gaussian có thể diễn giải, mở ra một hướng đầy hứa hẹn cho các backbone thị giác trong tương lai.