보도 자료 요약
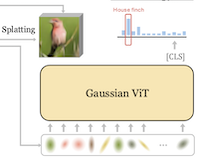
라이스 대학교와 UC Irvine의 연구자들은 신경망에 픽셀 또는 직사각형 패치의 그리드를 입력하는 기존 방식을 버리고, 그 입력을 2D Gaussian이라 불리는 소수의 수학적 블롭(blob) 집합으로 대체하는 새로운 이미지 분류 시스템을 구축했다. GViT라 불리는 이 시스템은 작은 인코더 네트워크를 학습시켜 각 이미지를 수백 개의 Gaussian으로 기술하는데, 각 블롭은 위치, 크기, 방향, 색상, 불투명도에 관한 정보를 담는다. 이 학습 설계의 영리한 점은 분류 모델과 Gaussian 인코더가 피드백 루프 안에서 함께 학습된다는 것이다. 즉, 분류기로부터 나오는 그래디언트 — 본질적으로 이미지의 어떤 부분이 내용을 식별하는 데 중요한지에 관한 신호 — 가 다시 피드백되어, Gaussian이 정보가 없는 배경 전체에 균일하게 퍼지도록 두는 대신 인식에 실제로 유용한 영역으로 향하도록 유도한다. 표준 ImageNet-1k 벤치마크에서 이 접근법을 사용했을 때, GViT의 최고 버전은 ViT-Base 아키텍처로 76.9%의 top-1 정확도에 도달했으며, 이는 비슷한 크기의 기존 패치 기반 ViT의 약 78.7%와 비교해 2퍼센트 포인트 미만의 격차에 불과하면서도 근본적으로 다르고 훨씬 더 간결한 입력 표현을 사용한 결과다. 이 연구가 중요한 이유는 기존 시스템을 즉시 능가하기 때문이 아니라, 중간 단계의 인간이 해석 가능한 기하학적 기본 요소가 경쟁력 있는 시각 인식을 뒷받침할 수 있음을 입증하기 때문이며, 부수적으로 학습된 Gaussian이 모델이 가장 변별적이라고 여기는 장면의 부분 주위에 모이는 경향이 있어, 픽셀 그리드 모델이 자연스럽게 제공하지 못하는 가벼운 형태의 설명 가능성을 제공한다는 점이다.
초록
우리는 기존의 픽셀 또는 패치 그리드 입력 표현 대신 학습 가능한 소수의 2D Gaussian 집합을 사용하는 분류 프레임워크인 GVIT를 소개한다. 각 이미지는 수백 개의 Gaussian으로 인코딩되며, 이들의 위치, 스케일, 방향, 색상, 불투명도는 해당 표현 위에서 학습되는 ViT 분류기와 함께 공동으로 최적화된다. 우리는 분류기의 그래디언트를 구성적 가이드로 재사용하여 Gaussian이 클래스에 두드러진 영역으로 향하도록 유도하는 한편, 미분 가능한 렌더러가 이미지 재구성 손실을 최적화한다. 우리는 2D Gaussian 입력 표현과 우리의 GVIT 가이드를 결합하여 비교적 표준적인 ViT 아키텍처를 사용함으로써 전통적인 패치 기반 ViT의 성능에 근접하게 일치함을 보이며, ViT-B 아키텍처를 사용하여 Imagenet-1k에서 76.9%의 top-1 정확도에 도달한다.
인용
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- GViT란 무엇이며 어떤 문제를 다루는가? GViT는 고정된 픽셀 또는 패치 그리드 입력을 학습 가능한 소수의 2D Gaussian 기본 요소 집합으로 대체하는 시각 인식 프레임워크로, 중간 수준의 기하학적 표현이 경쟁력 있는 이미지 분류를 뒷받침할 수 있는지를 검증한다.
- Gaussian은 어떻게 학습되는가? 디노이징 Gaussian 인코더가 Gaussian의 중심, 스케일, 방향, 색상, 불투명도를 예측하고, 미분 가능한 렌더러가 이미지 재구성을 최적화하며, ViT 분류기가 Gaussian을 클래스에 두드러진 영역으로 향하게 하는 구성적 그래디언트를 제공한다.
- GViT는 ImageNet-1k에서 얼마나 잘 작동하는가? 가이드를 적용한 GViT-B 모델은 ImageNet-1k에서 76.9퍼센트의 top-1 정확도에 도달하며, 이는 상당히 다른 Gaussian 입력 표현을 사용하면서도 비슷한 크기의 패치 기반 ViT-B/16에 대해 보고된 78.7퍼센트에 근접한 수치다.
- 분류기 그래디언트 가이드는 왜 중요한가? 논문은 가이드가 GViT-B를 ImageNet-1k에서 73.6퍼센트에서 76.9퍼센트로 향상시키고 더 작은 모델들도 유사하게 향상시킨다고 보고하며, 이는 작업을 인지한 Gaussian 배치가 해당 표현을 인식에 유용하게 만드는 데 핵심임을 보여준다.
- GViT는 해석 가능성의 이점을 제공하는가? 그렇다. 학습된 Gaussian 공분산과 클래스 변별적 어텐션 맵은 클래스 관련 이미지 영역에 집중되는 경향이 있어, 표준 패치 토큰이 자연스럽게 드러내지 못하는 기하학적 시각 설명을 표현에 부여한다.
주요 기여
- 이 논문은 픽셀, 패치, 원시 바이트, 압축된 주파수 계수가 아닌 2D Gaussian 기본 요소 집합에 기반한 ViT 호환 이미지 표현을 도입한다.
- GViT는 재구성 손실이 이미지 충실도를 보존하는 동시에 분류기 그래디언트가 Gaussian을 변별적 시각 증거 쪽으로 능동적으로 재배치하는 협력적 학습 방식을 제안한다.
- ImageNet-1k 실험은 Gaussian 입력이 ViT-B 백본으로 76.9퍼센트의 top-1 정확도에 도달할 수 있음을 보여주며, 이는 논문에 나열된 여러 비(非)패치 입력 대안을 능가하고 기존 패치 기반 ViT-B/16과 1.8포인트 이내로 좁혀진다.
- Mini-ImageNet-100에 대한 절제(ablation) 실험은 디노이징과 분류기 그래디언트 가이드가 Gaussian 배치를 유의미하게 개선함을 보여주며, 완전한 가이드 버전이 오프라인 Gaussian 피팅, 학습된 쿼리, 가이드 없는 디노이징을 능가한다.
- 분석은 Gaussian 스케일과 어텐션 신호가 클래스 변별적 영역과 정렬됨을 보여주며, GViT가 자연스러운 해석 가능성 요소를 갖춘 간결한 인식 표현을 제공한다는 주장을 뒷받침한다.
한계 및 유의 사항
- 패치 기반 ViT는 오늘날 많은 대규모 배포에서 여전히 가장 실용적인 선택이지만, ImageNet-1k에서 GViT의 작은 정확도 격차는 Gaussian 기본 요소가 이미 실현 가능하고 놀라울 만큼 경쟁력 있는 대안적 표현이라는 강력한 근거를 제시한다.
- Gaussian의 개수가 학습 이전에 고정되어 있으므로, 향후 버전은 동적 생성, 가지치기, 재할당에서 이점을 얻을 수 있다. Gaussian 예산이 증가할수록 관찰되는 단조로운 성능 향상은 그러한 다음 설계 단계에 유용한 지침을 제공한다.
- 미분 가능한 렌더링은 특히 고해상도이거나 ImageNet 규모의 학습에서 512개를 초과하는 Gaussian을 사용할 때 메모리와 연산 부담을 가중시킨다. 이는 핵심 아이디어의 약점이라기보다는 그 외에는 유망한 표현을 둘러싼 엔지니어링상의 병목이다.
- 실험은 탐지나 분할과 같은 밀집 예측 작업이 아니라 이미지 분류 및 전이 분류 벤치마크에 초점을 맞춘다. 클래스에 두드러진 Gaussian 배치는 그러한 작업이 이 표현을 다음으로 탐구하기에 자연스러운 영역임을 시사한다.
- 현재 접근법은 설계상 일부 세밀한 픽셀 디테일을 압축해 제거하는데, 이는 표현을 간결하고 해석 가능하게 만드는 데 도움이 되는 한편, 재구성 충실도와 의미적 변별력 사이의 균형을 조정하는 향후 연구의 여지를 남긴다.
이 결과를 읽는 방법
이 논문은 시각 인식이 반드시 픽셀이나 패치 그리드에 얽매일 필요가 없다는 강력한 근거 기반 주장으로 읽는 것이 가장 좋다. GViT는 ImageNet 성능을 표준 ViT에 근접하게 유지하면서도, 향후 비전 백본을 위한 유망한 방향을 여는 해석 가능한 Gaussian 표현을 도입한다.