CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
resumen
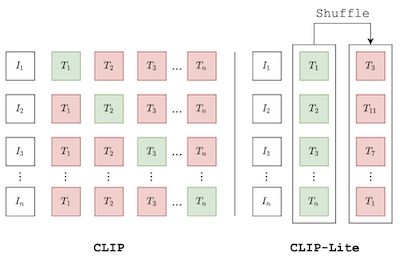
Proponemos CLIP-Lite, un método eficiente en información para el aprendizaje de representaciones visuales mediante la alineación de características con anotaciones textuales. En comparación con el modelo CLIP propuesto anteriormente, CLIP-Lite requiere solo un par negativo imagen-texto por cada par positivo imagen-texto durante la optimización de su objetivo de aprendizaje contrastivo. Lo logramos aprovechando una cota inferior eficiente en información para maximizar la información mutua entre las dos modalidades de entrada. Esto permite entrenar CLIP-Lite con cantidades de datos y tamaños de lote significativamente reducidos, obteniendo a la vez un mejor rendimiento que CLIP a la misma escala. Evaluamos CLIP-Lite mediante preentrenamiento en el conjunto de datos COCO-Captions y probando el aprendizaje por transferencia a otros conjuntos de datos. CLIP-Lite obtiene una ganancia absoluta de +14,0 % en mAP en la clasificación de Pascal VOC y una ganancia de +22,1 % en precisión top-1 en ImageNet, siendo comparable o superior a otros modelos supervisados por texto más complejos. CLIP-Lite también es superior a CLIP en la recuperación de imágenes y texto, la clasificación sin entrenamiento previo (zero-shot) y el anclaje visual. Por último, mostramos que CLIP-Lite puede aprovechar la semántica del lenguaje para fomentar representaciones visuales libres de sesgo que pueden utilizarse en tareas posteriores. Implementación: https://github.com/4m4n5/CLIP-Lite
cita
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}