초록
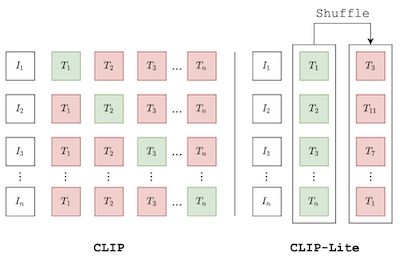
우리는 텍스트 주석과의 특징 정렬을 통한 시각 표현 학습을 위한 정보 효율적 방법인 CLIP-Lite를 제안한다. 이전에 제안된 CLIP 모델과 비교하여, CLIP-Lite는 대조 학습(contrastive learning) 목적함수의 최적화 과정에서 모든 양성 이미지-텍스트 샘플마다 단 하나의 음성 이미지-텍스트 샘플 쌍만을 요구한다. 우리는 두 입력 양식 간의 상호 정보(mutual information)를 최대화하기 위한 정보 효율적 하한(lower-bound)을 활용하여 이를 달성한다. 이를 통해 CLIP-Lite는 동일한 규모에서 CLIP보다 더 나은 성능을 얻으면서도 상당히 줄어든 데이터 양과 배치 크기로 학습될 수 있다. 우리는 COCO-Captions 데이터셋에서 사전학습한 뒤 다른 데이터셋으로의 전이 학습을 시험하여 CLIP-Lite를 평가한다. CLIP-Lite는 Pascal VOC 분류에서 성능상 +14.0% mAP의 절대적 향상을, ImageNet에서 +22.1% top-1 정확도 향상을 얻으며, 더 복잡한 다른 텍스트 지도 모델에 필적하거나 그보다 우수하다. CLIP-Lite는 또한 이미지 및 텍스트 검색, 제로샷 분류, 시각적 그라운딩에서 CLIP보다 우수하다. 마지막으로, 우리는 CLIP-Lite가 언어 의미론을 활용하여 다운스트림 작업에 사용될 수 있는 편향 없는 시각 표현을 촉진할 수 있음을 보인다. 구현: https://github.com/4m4n5/CLIP-Lite
인용
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}