CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
аннотация
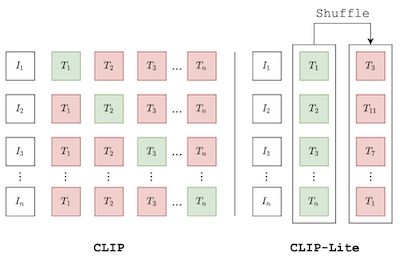
Мы предлагаем CLIP-Lite — информационно-эффективный метод обучения визуальных представлений посредством выравнивания признаков с текстовыми аннотациями. По сравнению с ранее предложенной моделью CLIP, CLIP-Lite требует лишь одной отрицательной пары изображение-текст на каждую положительную пару изображение-текст во время оптимизации своей контрастивной целевой функции. Мы достигаем этого, используя информационно-эффективную нижнюю границу для максимизации взаимной информации между двумя входными модальностями. Это позволяет обучать CLIP-Lite со значительно сниженными объёмами данных и размерами батчей, при этом достигая лучшей производительности, чем CLIP, в том же масштабе. Мы оцениваем CLIP-Lite путём предобучения на наборе данных COCO-Captions и тестирования Transfer Learning на других наборах данных. CLIP-Lite получает абсолютный прирост производительности +14.0% mAP на классификации Pascal VOC и прирост top-1 точности +22.1% на ImageNet, при этом будучи сопоставимым или превосходящим другие, более сложные, модели с текстовым надзором. CLIP-Lite также превосходит CLIP в поиске изображений и текста, классификации в режиме zero-shot и визуальной локализации. Наконец, мы показываем, что CLIP-Lite может использовать семантику языка для поощрения свободных от предвзятости визуальных представлений, которые могут применяться в целевых задачах. Реализация: https://github.com/4m4n5/CLIP-Lite
цитирование
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}