要旨
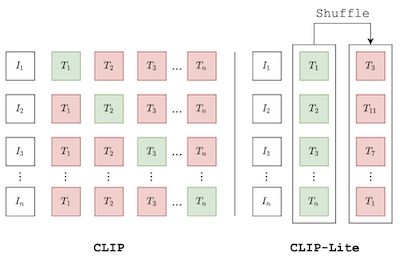
我々は、テキスト注釈との特徴アラインメントによる視覚表現学習のための情報効率的な手法であるCLIP-Liteを提案します。従来提案されたCLIPモデルと比較して、CLIP-Liteは対照学習目的関数の最適化中に、正の画像・テキストサンプルペア1つに対して負の画像・テキストサンプルペアを1つだけ必要とします。これは、2つの入力モダリティ間の相互情報量を最大化するための情報効率的な下界を活用することで実現されます。これにより、CLIP-Liteは大幅に削減されたデータ量とバッチサイズで学習できる一方で、同じ規模のCLIPよりも優れた性能を得られます。我々はCOCO-Captionsデータセットで事前学習し、他のデータセットへの転移学習をテストすることでCLIP-Liteを評価します。CLIP-Liteは、Pascal VOC分類で+14.0%のmAP絶対性能向上、ImageNetで+22.1%のtop-1精度向上を達成し、より複雑な他のテキスト教師ありモデルと同等またはそれ以上の性能を示します。CLIP-Liteはまた、画像・テキスト検索、ゼロショット分類、ビジュアルグラウンディングにおいてもCLIPを上回ります。最後に、CLIP-Liteが言語の意味を活用して、下流タスクで利用できるバイアスのない視覚表現を促進できることを示します。実装:https://github.com/4m4n5/CLIP-Lite
引用
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}