摘要
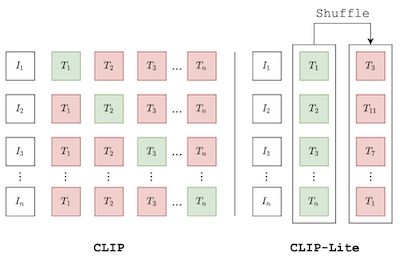
我们提出了 CLIP-Lite,这是一种通过与文本标注进行特征对齐来进行视觉表示学习的信息高效方法。与此前提出的 CLIP 模型相比,CLIP-Lite 在优化其对比学习目标的过程中,对于每个正样本图像-文本对仅需一个负样本图像-文本对。我们通过利用一个信息高效的下界来最大化两种输入模态之间的互信息,从而实现这一点。这使得 CLIP-Lite 能够在显著减少的数据量和批量大小下进行训练,同时在相同规模下获得优于 CLIP 的性能。我们通过在 COCO-Captions 数据集上预训练并测试向其他数据集的迁移学习来评估 CLIP-Lite。CLIP-Lite 在 Pascal VOC 分类上取得了 +14.0% 的 mAP 绝对提升,在 ImageNet 上取得了 +22.1% 的 top-1 准确率提升,同时与其他更复杂的文本监督模型相当或更优。CLIP-Lite 在图像与文本检索、零样本分类以及视觉接地(visual grounding)方面也优于 CLIP。最后,我们表明 CLIP-Lite 能够利用语言语义来促成可用于下游任务的无偏视觉表示。实现:https://github.com/4m4n5/CLIP-Lite
引用
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}