MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Resumen de prensa
Investigadores de Meta y la Universidad Rice han desarrollado MetaEmbed, un nuevo enfoque para la búsqueda multimodal que permite a los sistemas ajustar su precisión y velocidad bajo demanda. Los sistemas actuales de recuperación multimodal, que buscan a través de texto e imágenes, enfrentan un compromiso entre precisión y eficiencia computacional: o bien comprimen todo en un único vector que pierde detalle, o bien usan cientos de vectores que se vuelven demasiado lentos para un uso práctico. MetaEmbed introduce "Meta Tokens" aprendibles que crean un pequeño conjunto de incrustaciones contextualizadas organizadas de información de grano grueso a grano fino. Este diseño permite a los usuarios seleccionar cuántos vectores usar durante la búsqueda, equilibrando la calidad frente a los requisitos de velocidad. Las pruebas en benchmarks estándar muestran que el sistema logra un rendimiento de vanguardia mientras escala
resumen
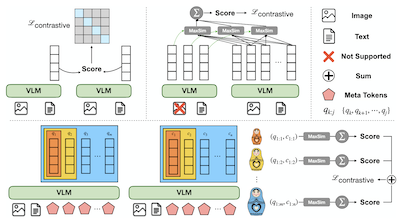
Los modelos universales de incrustación multimodal han logrado un gran éxito en la captura de la relevancia semántica entre consultas y candidatos. Sin embargo, los métodos actuales o bien condensan las consultas y los candidatos en un único vector, lo que potencialmente limita la expresividad para información de grano fino, o bien producen demasiados vectores que resultan prohibitivos para la recuperación multivectorial. En este trabajo, presentamos MetaEmbed, un nuevo marco para la recuperación multimodal que replantea cómo se construyen las incrustaciones multimodales y cómo se interactúa con ellas a escala. Durante el entrenamiento, se añade un número fijo de Meta Tokens aprendibles a la secuencia de entrada. En el momento de la prueba, sus representaciones contextualizadas de la última capa sirven como incrustaciones multivectoriales compactas pero expresivas. Mediante el entrenamiento propuesto de Matryoshka Multi-Vector Retrieval, MetaEmbed aprende a organizar la información por granularidad a través de múltiples vectores. Como resultado, habilitamos el escalado en el momento de la prueba en la recuperación multimodal, donde los usuarios pueden equilibrar la calidad de recuperación frente a las exigencias de eficiencia seleccionando el número de tokens utilizados para la indexación y las interacciones de recuperación. Evaluaciones exhaustivas en el Massive Multimodal Embedding Benchmark (MMEB) y el Visual Document Retrieval Benchmark (ViDoRe) confirman que MetaEmbed logra un rendimiento de recuperación de vanguardia mientras escala de forma robusta a modelos con 32B de parámetros. El código está disponible en https://github.com/facebookresearch/MetaEmbed.
detalles
cita
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es MetaEmbed y qué problema aborda? MetaEmbed es un marco de recuperación multimodal que utiliza Meta Tokens aprendibles y compactos para proporcionar una recuperación más expresiva que las incrustaciones de un solo vector sin el alto costo de cientos de vectores a nivel de parche.
- ¿Cómo habilita MetaEmbed el escalado en el momento de la prueba? Entrena grupos anidados de Meta Embeddings mediante Matryoshka Multi-Vector Retrieval, de modo que los usuarios pueden elegir presupuestos de recuperación más pequeños o más grandes en el momento de la indexación y la puntuación sin reentrenar.
- ¿Por qué son útiles los Meta Tokens para la recuperación multimodal? Sus estados contextualizados de la última capa actúan como un pequeño conjunto de incrustaciones multivectoriales que preservan las interacciones de grano fino entre consulta y candidato manteniendo controlables el tamaño del índice y el costo de puntuación.
- ¿Qué tan bien rinde MetaEmbed en MMEB? El artículo reporta que MetaEmbed inicializado con Qwen2.5-VL alcanza un Precision@1 global de 76.6 con un modelo de 7B y de 78.7 con un modelo de 32B, superando a las líneas base listadas.
- ¿Funciona MetaEmbed para la recuperación de documentos visuales? Sí, el artículo lo evalúa en ViDoRe y muestra que la calidad de recuperación mejora a medida que se usan más Meta Embeddings, mientras que MMR preserva un rendimiento sólido con presupuestos de recuperación bajos.
Contribuciones principales
- El artículo introduce los Meta Tokens como incrustaciones multivectoriales contextualizadas y compactas para la recuperación multimodal a través de consultas y candidatos de texto, imagen y modalidad mixta.
- Matryoshka Multi-Vector Retrieval entrena grupos de incrustaciones anidados de grano grueso a grano fino, lo que permite que un único modelo y diseño de índice admitan múltiples puntos de operación de calidad-latencia.
- MetaEmbed logra resultados de vanguardia en MMEB y resultados sólidos en ViDoRe mientras escala a backbones de modelos de visión y lenguaje de 32B.
- Las ablaciones muestran que los beneficios de la recuperación multivectorial crecen con la escala del modelo y que MMR es importante para preservar la calidad de recuperación con presupuestos bajos.
- El análisis de eficiencia muestra que la latencia de puntuación permanece pequeña para presupuestos moderados y que la memoria del índice puede gestionarse eligiendo configuraciones de recuperación equilibradas.
Limitaciones y advertencias
- Los presupuestos de recuperación más altos aumentan la memoria del índice, pero el diseño anidado hace de esto un compromiso controlable por el usuario en lugar de un costo de despliegue fijo.
- El presupuesto más grande puede aumentar sustancialmente los FLOPs de puntuación, pero la latencia medida se mantiene práctica para muchos escenarios y el artículo muestra una precisión útil con presupuestos mucho menores.
- MetaEmbed aún requiere el ajuste fino de backbones VLM potentes, por lo que trabajos futuros podrían explorar recetas de entrenamiento más ligeras; la configuración con LoRA y los experimentos con múltiples arquitecturas ya hacen que el enfoque sea ampliamente accesible.
- La evaluación se centra en benchmarks estándar de recuperación multimodal y de documentos visuales, dejando los índices de producción muy grandes y los dominios empresariales especializados como estudios de despliegue naturales.
- El método se orienta a la recuperación en lugar de a la generación o la respuesta a preguntas directamente, pero una mejor recuperación flexible es un bloque de construcción valioso para los sistemas multimodales aumentados por recuperación.
Cómo interpretar este resultado
Este artículo se lee mejor como una contribución sólida a la recuperación multimodal escalable: MetaEmbed preserva la interacción tardía de grano fino, añade un control práctico de presupuesto en el momento de la prueba y muestra que los VLM más grandes pueden convertirse en modelos de recuperación más eficaces cuando se les proporcionan interfaces multivectoriales compactas.