MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu tại Meta và Rice University đã phát triển MetaEmbed, một phương pháp mới cho tìm kiếm đa phương thức cho phép các hệ thống điều chỉnh độ chính xác và tốc độ theo nhu cầu. Các hệ thống truy hồi đa phương thức hiện tại, vốn tìm kiếm xuyên qua văn bản và ảnh, phải đối mặt với sự đánh đổi giữa độ chính xác và hiệu quả tính toán — chúng hoặc nén mọi thứ thành một vector duy nhất làm mất chi tiết, hoặc sử dụng hàng trăm vector khiến chúng trở nên quá chậm để dùng trong thực tế. MetaEmbed giới thiệu các "Meta Token" có thể học được, tạo ra một tập nhỏ các embedding theo ngữ cảnh được tổ chức từ thông tin thô đến thông tin chi tiết. Thiết kế này cho phép người dùng chọn số lượng vector dùng trong quá trình tìm kiếm, cân bằng chất lượng với các yêu cầu về tốc độ. Việc kiểm tra trên các benchmark tiêu chuẩn cho thấy hệ thống đạt được hiệu năng tốt nhất hiện nay trong khi mở rộng quy mô
tóm tắt
Các mô hình embedding đa phương thức phổ quát đã đạt được thành công lớn trong việc nắm bắt mức độ liên quan ngữ nghĩa giữa các truy vấn và các ứng viên. Tuy nhiên, các phương pháp hiện tại hoặc cô đọng các truy vấn và ứng viên thành một vector duy nhất, có khả năng hạn chế tính biểu đạt cho thông tin chi tiết, hoặc tạo ra quá nhiều vector khiến cho việc truy hồi đa vector trở nên không khả thi. Trong công trình này, chúng tôi giới thiệu MetaEmbed, một khung mới cho truy hồi đa phương thức nhằm tái tư duy về cách các embedding đa phương thức được xây dựng và tương tác ở quy mô lớn. Trong quá trình huấn luyện, một số lượng cố định các Meta Token có thể học được được thêm vào chuỗi đầu vào. Tại thời điểm kiểm tra, các biểu diễn theo ngữ cảnh ở lớp cuối của chúng đóng vai trò là các embedding đa vector vừa cô đọng vừa giàu tính biểu đạt. Thông qua phương pháp huấn luyện Matryoshka Multi-Vector Retrieval được đề xuất, MetaEmbed học cách tổ chức thông tin theo độ chi tiết trên nhiều vector. Kết quả là, chúng tôi cho phép mở rộng quy mô tại thời điểm kiểm tra trong truy hồi đa phương thức, nơi người dùng có thể cân bằng giữa chất lượng truy hồi và nhu cầu hiệu quả bằng cách chọn số lượng token được dùng cho việc lập chỉ mục và các tương tác truy hồi. Các đánh giá rộng rãi trên Massive Multimodal Embedding Benchmark (MMEB) và Visual Document Retrieval Benchmark (ViDoRe) xác nhận rằng MetaEmbed đạt được hiệu năng truy hồi tốt nhất hiện nay trong khi mở rộng quy mô một cách vững chắc tới các mô hình có 32B tham số. Mã nguồn có tại https://github.com/facebookresearch/MetaEmbed.
chi tiết
trích dẫn
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
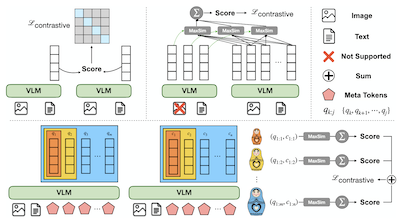
- MetaEmbed là gì và nó giải quyết vấn đề gì? MetaEmbed là một khung truy hồi đa phương thức sử dụng các Meta Token có thể học được, cô đọng để cung cấp khả năng truy hồi giàu tính biểu đạt hơn so với các embedding đơn vector mà không phải chịu chi phí nặng nề của hàng trăm vector ở cấp độ patch.
- MetaEmbed cho phép mở rộng quy mô tại thời điểm kiểm tra như thế nào? Nó huấn luyện các nhóm Meta Embedding lồng nhau thông qua Matryoshka Multi-Vector Retrieval, để người dùng có thể chọn ngân sách truy hồi nhỏ hơn hoặc lớn hơn tại thời điểm lập chỉ mục và tính điểm mà không cần huấn luyện lại.
- Tại sao các Meta Token lại hữu ích cho truy hồi đa phương thức? Các trạng thái theo ngữ cảnh ở lớp cuối của chúng đóng vai trò là một tập nhỏ các embedding đa vector, bảo toàn các tương tác truy vấn-ứng viên chi tiết trong khi vẫn giữ kích thước chỉ mục và chi phí tính điểm có thể kiểm soát được.
- MetaEmbed hoạt động tốt đến mức nào trên MMEB? Bài báo báo cáo rằng MetaEmbed được khởi tạo từ Qwen2.5-VL đạt 76,6 Precision@1 tổng thể với mô hình 7B và 78,7 với mô hình 32B, vượt trội hơn các baseline được liệt kê.
- MetaEmbed có hoạt động cho truy hồi tài liệu thị giác không? Có, bài báo đánh giá trên ViDoRe và cho thấy chất lượng truy hồi cải thiện khi sử dụng nhiều Meta Embedding hơn, trong khi MMR bảo toàn hiệu năng mạnh ở các ngân sách truy hồi thấp.
Đóng góp chính
- Bài báo giới thiệu các Meta Token như là các embedding đa vector theo ngữ cảnh, cô đọng cho truy hồi đa phương thức trên các truy vấn và ứng viên dạng văn bản, ảnh và đa phương thức hỗn hợp.
- Matryoshka Multi-Vector Retrieval huấn luyện các nhóm embedding lồng nhau theo lối từ thô đến chi tiết, cho phép một thiết kế mô hình và chỉ mục duy nhất hỗ trợ nhiều điểm vận hành về chất lượng-độ trễ.
- MetaEmbed đạt được các kết quả tốt nhất hiện nay trên MMEB và các kết quả mạnh trên ViDoRe trong khi mở rộng quy mô tới các backbone mô hình thị giác-ngôn ngữ 32B.
- Các phân tích loại bỏ cho thấy lợi ích của truy hồi đa vector tăng lên theo quy mô mô hình và rằng MMR là quan trọng để bảo toàn chất lượng truy hồi ở ngân sách thấp.
- Phân tích hiệu quả cho thấy độ trễ tính điểm vẫn nhỏ với các ngân sách vừa phải và rằng bộ nhớ chỉ mục có thể được quản lý bằng cách chọn các thiết lập truy hồi cân bằng.
Hạn chế và lưu ý
- Các ngân sách truy hồi cao hơn làm tăng bộ nhớ chỉ mục, nhưng thiết kế lồng nhau khiến đây trở thành một sự đánh đổi mà người dùng có thể kiểm soát thay vì một chi phí triển khai cố định.
- Ngân sách lớn nhất có thể làm tăng đáng kể số FLOPs tính điểm, nhưng độ trễ được đo vẫn thực tế cho nhiều bối cảnh và bài báo cho thấy độ chính xác hữu ích ở các ngân sách nhỏ hơn nhiều.
- MetaEmbed vẫn yêu cầu tinh chỉnh các backbone VLM mạnh, vì vậy công trình tương lai có thể khám phá các công thức huấn luyện nhẹ hơn; thiết lập LoRA và các thí nghiệm đa kiến trúc đã làm cho phương pháp này dễ tiếp cận rộng rãi.
- Việc đánh giá tập trung vào các benchmark truy hồi đa phương thức và tài liệu thị giác tiêu chuẩn, để dành các chỉ mục sản xuất rất lớn và các miền doanh nghiệp chuyên biệt làm các nghiên cứu triển khai tự nhiên.
- Phương pháp nhắm vào việc truy hồi thay vì sinh hoặc trả lời câu hỏi một cách trực tiếp, nhưng việc truy hồi linh hoạt tốt hơn là một khối xây dựng có giá trị cho các hệ thống đa phương thức tăng cường bằng truy hồi.
Cách diễn giải kết quả này
Bài báo này nên được hiểu như một đóng góp mạnh mẽ cho lĩnh vực truy hồi đa phương thức có thể mở rộng quy mô: MetaEmbed bảo toàn tương tác muộn chi tiết, bổ sung một núm điều chỉnh ngân sách thực tế tại thời điểm kiểm tra, và cho thấy rằng các VLM lớn hơn có thể trở thành các mô hình truy hồi hiệu quả hơn khi được trao các giao diện đa vector cô đọng.