MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Résumé du communiqué de presse
Des chercheurs de Meta et de l'université Rice ont mis au point MetaEmbed, une nouvelle approche de la recherche multimodale qui permet aux systèmes d'ajuster leur précision et leur vitesse à la demande. Les systèmes actuels de recherche multimodale, qui effectuent des recherches à travers le texte et les images, sont confrontés à un compromis entre précision et efficacité computationnelle : ils compressent soit tout en un seul vecteur qui perd des détails, soit utilisent des centaines de vecteurs qui deviennent trop lents pour un usage pratique. MetaEmbed introduit des « Meta Tokens » apprenables qui créent un petit ensemble de plongements contextualisés organisés de l'information grossière à l'information à grain fin. Cette conception permet aux utilisateurs de choisir combien de vecteurs utiliser lors de la recherche, équilibrant la qualité par rapport aux exigences de vitesse. Les tests sur des bancs d'essai standard montrent que le système atteint des performances de pointe tout en passant à l'échelle
résumé
Les modèles universels de plongement multimodal ont remporté un grand succès dans la capture de la pertinence sémantique entre requêtes et candidats. Cependant, les méthodes actuelles condensent soit les requêtes et les candidats en un seul vecteur, ce qui peut limiter l'expressivité pour les informations à grain fin, soit produisent trop de vecteurs, ce qui est prohibitif pour la recherche multi-vecteurs. Dans ce travail, nous présentons MetaEmbed, un nouveau cadre de recherche multimodale qui repense la manière dont les plongements multimodaux sont construits et exploités à grande échelle. Pendant l'entraînement, un nombre fixe de Meta Tokens apprenables est ajouté à la séquence d'entrée. Au moment du test, leurs représentations contextualisées de dernière couche servent de plongements multi-vecteurs compacts mais expressifs. Grâce à l'entraînement Matryoshka Multi-Vector Retrieval proposé, MetaEmbed apprend à organiser l'information par granularité à travers plusieurs vecteurs. Nous permettons ainsi une mise à l'échelle au moment du test dans la recherche multimodale, où les utilisateurs peuvent équilibrer la qualité de recherche et les exigences d'efficacité en sélectionnant le nombre de tokens utilisés pour l'indexation et les interactions de recherche. Des évaluations approfondies sur le Massive Multimodal Embedding Benchmark (MMEB) et le Visual Document Retrieval Benchmark (ViDoRe) confirment que MetaEmbed atteint des performances de recherche de pointe tout en passant à l'échelle de manière robuste jusqu'à des modèles de 32 milliards de paramètres. Le code est disponible à l'adresse https://github.com/facebookresearch/MetaEmbed.
détails
citation
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
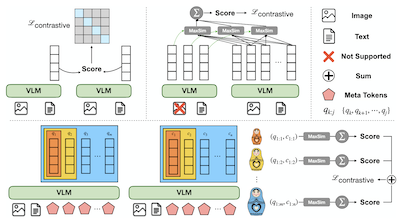
- Qu'est-ce que MetaEmbed et quel problème résout-il ? MetaEmbed est un cadre de recherche multimodale qui utilise des Meta Tokens apprenables et compacts pour offrir une recherche plus expressive que les plongements à vecteur unique, sans le coût élevé de centaines de vecteurs au niveau des patchs.
- Comment MetaEmbed permet-il la mise à l'échelle au moment du test ? Il entraîne des groupes imbriqués de Meta Embeddings grâce à Matryoshka Multi-Vector Retrieval, de sorte que les utilisateurs peuvent choisir des budgets de recherche plus petits ou plus grands au moment de l'indexation et du calcul des scores, sans réentraînement.
- Pourquoi les Meta Tokens sont-ils utiles pour la recherche multimodale ? Leurs états contextualisés de dernière couche agissent comme un petit ensemble de plongements multi-vecteurs qui préservent les interactions à grain fin entre requête et candidat tout en gardant la taille de l'index et le coût de calcul des scores contrôlables.
- Quelles sont les performances de MetaEmbed sur MMEB ? L'article rapporte que MetaEmbed initialisé avec Qwen2.5-VL atteint une Precision@1 globale de 76,6 avec un modèle de 7 milliards de paramètres et de 78,7 avec un modèle de 32 milliards de paramètres, surpassant les références listées.
- MetaEmbed fonctionne-t-il pour la recherche de documents visuels ? Oui, l'article évalue sur ViDoRe et montre que la qualité de recherche s'améliore à mesure que davantage de Meta Embeddings sont utilisés, tandis que MMR préserve de solides performances avec de faibles budgets de recherche.
Principales contributions
- L'article introduit les Meta Tokens comme plongements multi-vecteurs contextualisés et compacts pour la recherche multimodale à travers des requêtes et des candidats de modalité textuelle, visuelle et mixte.
- Matryoshka Multi-Vector Retrieval entraîne des groupes de plongements imbriqués du grossier au fin, permettant à une conception unique de modèle et d'index de prendre en charge plusieurs points de fonctionnement qualité-latence.
- MetaEmbed obtient des résultats de pointe sur MMEB et de solides résultats sur ViDoRe tout en passant à l'échelle de modèles vision-langage de 32 milliards de paramètres.
- Les ablations montrent que les bénéfices de la recherche multi-vecteurs augmentent avec l'échelle du modèle et que MMR est important pour préserver la qualité de recherche à faible budget.
- L'analyse d'efficacité montre que la latence de calcul des scores reste faible pour des budgets modérés et que la mémoire de l'index peut être gérée en choisissant des paramètres de recherche équilibrés.
Limites et mises en garde
- Des budgets de recherche plus élevés augmentent la mémoire de l'index, mais la conception imbriquée fait de cela un compromis contrôlable par l'utilisateur plutôt qu'un coût de déploiement fixe.
- Le budget le plus important peut augmenter substantiellement les FLOPs de calcul des scores, mais la latence mesurée reste praticable pour de nombreux paramètres et l'article montre une précision utile avec des budgets bien plus faibles.
- MetaEmbed nécessite toujours d'affiner de solides architectures de VLM, de sorte que des travaux futurs pourraient explorer des recettes d'entraînement plus légères ; la configuration LoRA et les expériences multi-architectures rendent déjà l'approche largement accessible.
- L'évaluation se concentre sur des bancs d'essai standard de recherche multimodale et de documents visuels, laissant les très grands index de production et les domaines spécialisés d'entreprise comme études de déploiement naturelles.
- La méthode cible la recherche plutôt que la génération ou la réponse à des questions directement, mais une meilleure recherche flexible constitue une brique précieuse pour les systèmes multimodaux augmentés par la recherche.
Comment interpréter ce résultat
Cet article se lit avant tout comme une contribution solide à la recherche multimodale passant à l'échelle : MetaEmbed préserve l'interaction tardive à grain fin, ajoute un levier pratique de budget au moment du test et montre que des VLM plus grands peuvent devenir des modèles de recherche plus efficaces lorsqu'on leur fournit des interfaces multi-vecteurs compactes.