MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Краткое изложение пресс-релиза
Исследователи из Meta и Rice University разработали MetaEmbed — новый подход к мультимодальному поиску, который позволяет системам по запросу регулировать свою точность и скорость. Современные системы мультимодального поиска, которые ведут поиск по тексту и изображениям, сталкиваются с компромиссом между точностью и вычислительной эффективностью: они либо сжимают всё в единый вектор, теряющий детали, либо используют сотни векторов, которые становятся слишком медленными для практического применения. MetaEmbed вводит обучаемые «Meta Tokens», которые создают небольшой набор контекстуализированных эмбеддингов, организованных от грубой к детальной информации. Такой дизайн позволяет пользователям выбирать, сколько векторов использовать во время поиска, балансируя качество и требования к скорости. Тестирование на стандартных бенчмарках показывает, что система достигает современного уровня качества, при этом масштабируясь
аннотация
Универсальные мультимодальные модели эмбеддингов добились большого успеха в захвате семантической релевантности между запросами и кандидатами. Однако современные методы либо сжимают запросы и кандидатов в единый вектор, потенциально ограничивая выразительность для детальной информации, либо порождают слишком много векторов, что недопустимо для многовекторного поиска. В этой работе мы представляем MetaEmbed — новый фреймворк для мультимодального поиска, который переосмысляет то, как мультимодальные эмбеддинги конструируются и взаимодействуют при масштабировании. Во время обучения фиксированное число обучаемых Meta Tokens добавляется к входной последовательности. На этапе тестирования их контекстуализированные представления последнего слоя служат компактными, но выразительными многовекторными эмбеддингами. Благодаря предложенному обучению Matryoshka Multi-Vector Retrieval MetaEmbed учится организовывать информацию по уровню детализации в нескольких векторах. В результате мы обеспечиваем масштабирование на этапе тестирования в мультимодальном поиске, где пользователи могут балансировать качество поиска и требования к эффективности, выбирая число токенов, используемых для индексации и поисковых взаимодействий. Обширные оценки на Massive Multimodal Embedding Benchmark (MMEB) и Visual Document Retrieval Benchmark (ViDoRe) подтверждают, что MetaEmbed достигает современного уровня качества поиска, при этом устойчиво масштабируясь до моделей с 32B параметрами. Код доступен по адресу https://github.com/facebookresearch/MetaEmbed.
подробности
цитирование
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
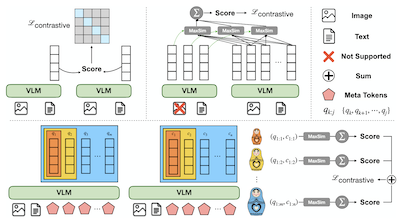
- Что такое MetaEmbed и какую проблему он решает? MetaEmbed — это фреймворк мультимодального поиска, который использует компактные обучаемые Meta Tokens, чтобы обеспечить более выразительный поиск, чем одновекторные эмбеддинги, без больших затрат, связанных с сотнями векторов уровня патчей.
- Как MetaEmbed обеспечивает масштабирование на этапе тестирования? Он обучает вложенные группы Meta Embeddings посредством Matryoshka Multi-Vector Retrieval, поэтому пользователи могут выбирать меньшие или большие бюджеты поиска на этапе индексации и оценки без переобучения.
- Почему Meta Tokens полезны для мультимодального поиска? Их контекстуализированные состояния последнего слоя действуют как небольшой набор многовекторных эмбеддингов, сохраняющих детальные взаимодействия запрос-кандидат, при этом удерживая под контролем размер индекса и стоимость оценки.
- Насколько хорошо MetaEmbed работает на MMEB? В статье сообщается, что MetaEmbed, инициализированный Qwen2.5-VL, достигает общего Precision@1 в 76.6 с моделью 7B и 78.7 с моделью 32B, превосходя перечисленные базовые модели.
- Работает ли MetaEmbed для поиска по визуальным документам? Да, в статье проводится оценка на ViDoRe и показывается, что качество поиска улучшается по мере использования большего числа Meta Embeddings, при этом MMR сохраняет высокое качество при низких бюджетах поиска.
Основные вклады
- В статье представлены Meta Tokens как компактные контекстуализированные многовекторные эмбеддинги для мультимодального поиска по текстовым, графическим и смешанным запросам и кандидатам.
- Matryoshka Multi-Vector Retrieval обучает вложенные группы эмбеддингов от грубых к детальным, позволяя единой модели и схеме индекса поддерживать несколько рабочих точек по качеству и задержке.
- MetaEmbed достигает современного уровня результатов на MMEB и высоких результатов на ViDoRe, при этом масштабируясь до бэкбонов моделей зрения и языка на 32B параметров.
- Абляции показывают, что преимущества многовекторного поиска растут с масштабом модели и что MMR важен для сохранения качества поиска при низком бюджете.
- Анализ эффективности показывает, что задержка оценки остаётся небольшой при умеренных бюджетах и что памятью индекса можно управлять, выбирая сбалансированные настройки поиска.
Ограничения и предостережения
- Более высокие бюджеты поиска увеличивают память индекса, но вложенный дизайн делает это управляемым пользователем компромиссом, а не фиксированной стоимостью развёртывания.
- Самый большой бюджет может существенно увеличить FLOPs оценки, однако измеренная задержка остаётся практичной для многих сценариев, и в статье показана полезная точность при гораздо меньших бюджетах.
- MetaEmbed всё ещё требует дообучения сильных бэкбонов VLM, поэтому будущая работа могла бы исследовать более лёгкие рецепты обучения; настройка LoRA и эксперименты с несколькими архитектурами уже делают подход широко доступным.
- Оценка сосредоточена на стандартных бенчмарках мультимодального поиска и поиска по визуальным документам, оставляя очень крупные продакшн-индексы и специализированные корпоративные домены естественными исследованиями развёртывания.
- Метод нацелен на поиск, а не напрямую на генерацию или ответы на вопросы, но более качественный гибкий поиск — ценный строительный блок для мультимодальных систем с генерацией, дополненной поиском.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильный вклад в масштабируемый мультимодальный поиск: MetaEmbed сохраняет детальное позднее взаимодействие, добавляет практичный регулятор бюджета на этапе тестирования и показывает, что более крупные VLM могут становиться более эффективными поисковыми моделями, если им предоставить компактные многовекторные интерфейсы.